
The best way to deploy a new version, either in the cloud or in your data center
Updating and configuring applications in a production environment is often scary. With so many available options, how can you choose the best deployment strategy for your use case?
Deployment strategies are used to upgrade or configure a running application. In The following article, we will discuss three deployment strategies:
- Recreate Deployment: the current version is terminated before deploying the new one.
- Blue/Green Deployment: the current and the new version run in parallel, then all traffic shifts to the new version.
- Canary Deployment: the new version rolls out incrementally to a subset of users, then is released to all users.
It’s worth noting that there are many other ways to release a new version of your application. You can find a discussion of some of them here.
Throughout the article, we’ll use a local Kubernetes environment to demonstrate the various deployment strategies being discussed.
You can also use a cloud environment if that’s an option.
All the required files and commands for the demonstration are mentioned below and can be found on this project’s Github repository.
As a side note, using Kubernetes to support CI builds was already discussed in a blog by Ori Hoch (see part 1 and part 2). In this post, we focus more on the CD part of CI/CD – that is, deployment.
Let’s take a look at our Kubernetes YAML files:
version1-deployment.yml – Deployment of 6 replicas running a simple web app presenting “version 1”
# version1-deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-1
spec:
selector:
matchLabels:
app: nginx
version: 'v1.0'
replicas: 6
template:
metadata:
labels:
app: nginx
version: 'v1.0'
spec:
containers:
- name: nginx
image: my_project/web-app:version1
ports:
- containerPort: 80
version2-deployment.yml Deployment – Deployment of 6 replicas running a simple web app presenting “version 2”
# version2-deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-2
spec:
selector:
matchLabels:
app: nginx
version: 'v1.1'
replicas: 6
template:
metadata:
labels:
app: nginx
version: 'v1.1'
spec:
containers:
- name: nginx
image: my_project/web-app:version2
ports:
- containerPort: 80 production-service.yml – The production service of our application. Users will access the first version of the application (version1) using this service.
# production-service.yml
apiVersion: v1
kind: Service
metadata:
name: production-service
spec:
type: LoadBalancer
selector:
app: nginx
version: 'v1.0'
ports:
- protocol: TCP
port: 80
targetPort: 80 Recreate deployment (basic deployment)
Have you ever asked yourself, “what is the worst way to deploy my application?”
If you have, the answer is Recreate deployment.
Jokes aside, there are some valid use cases for this method.
For example, upgrading a complicated microservices-based application while having multiple versions running in parallel can cause data loss or serious networking issues.
In this method, the current version must be shut down completely before deploying the new one. Users will experience downtime in the period between the current version being down and the new one fully deployed.
Of all the deployment strategies we’re discussing, this is the easiest and cheapest to implement, but also the riskiest. In case the new version has a serious bug, all the users will notice it, and any necessary rollbacks will cause more downtime.
Why should I use this deployment strategy?
- My application’s data is important and I can’t afford data loss or serious networking issues
- I must run migrations before the new application starts
- My application doesn’t support multiple versions in parallel
- I am working in a testing environment
- Users use my app only in a specific timeframe (like a customer service app that works 9:00-17:00)
- I am low on budget
Pros:
- Low price
- Easy to implement
- Add use case
Cons:
- Downtime will occur
- High production risk
- Slow rollback speed

To implement recreate deployment:
- Deploy the first version of the application
kubectl apply -f version1-deployment.yml && kubectl rollout status -f version1-deployment.yml - Apply the production service
kubectl apply -f production-service.yml - Delete the first version of the application
kubectl delete -f version1-deployment.yml - After the first version is completely deleted, deploy the new version of the application
kubectl apply -f version2-deployment.yml && kubectl rollout status -f version2-deployment.yml - Now, all that’s left is to change the service to point to the new version
kubectl patch service production-service --patch '{"spec": {"selector": {"version": "v1.1"}}}'
If downtime is your biggest concern, consider using the next method.
Blue/Green deployment
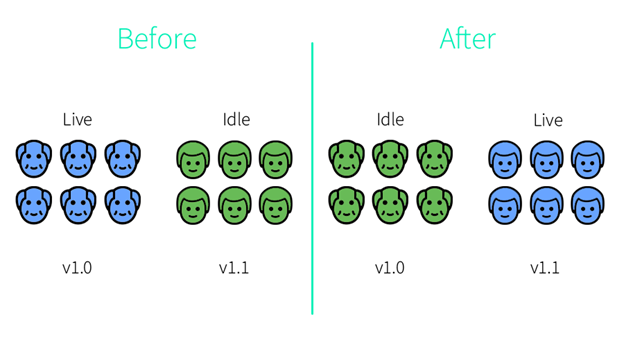
A Blue-Green deployment, also known as red-black (bonus points if you guess who embedded this term*), is a zero-downtime deployment strategy where the current version (the blue instance) and the new version (the green instance) of the application run in parallel in the production environment. Both versions run simultaneously, but the exposed application’s service only points to the current version.
The new version needs to be tested in the environment before users access it. When it meets all the requirements, all that is left is to change the application’s service to point to the green instance.
*(If you haven’t guessed yet, it was Netflix! You can read more about it here).
From this point, the older version runs as a backup alongside the new version. In case of a failure, rolling back is easy – you simply switch the traffic from the green instance to the blue one.
After the deployment succeeds and the blue instance is deleted, the green instance will act as the blue one in the next update.
When should I use this deployment strategy?
- I don’t want my users to experience any downtime
- I can roll back to the previous version quickly and easily
- My infrastructure is scalable and I can handle the costs of having 2 applications running simultaneously
- I want to save the previous version to use for future developments
Pros:
- zero downtime
- Easy and quick rollback
- All users experience the same version (prevention of versioning issue)
- Allows testing of old vs. new versions
Cons:
- Infrastructure costs might increase as it requires double the resources
- Probably will not fit for minor version changes
- Requires testing and monitoring the green instance before releasing it to production
To implement blue-green deployment:
- Apply the blue instance’s deployment
kubectl apply -f version1-deployment.yml && kubectl rollout status -f version1-deployment.yml - Apply the green instance’s deployment
kubectl apply -f version2-deployment.yml && kubectl rollout status -f version2-deployment.yml - Apply the production service
kubectl apply -f production-service.yml - Run tests on the green instance
- If issues were discovered in the new version during testing, Delete the new version’s deployment
kubectl delete -f version2-deployment.ymland fix the application’s code before redeploying.
- If the new version testing was successful and the version is production-ready, change the service to point to the green instance
kubectl patch service production-service --patch '{"spec": {"selector": {"version": "v1.1"}}}'
- If issues were discovered in the new version during testing, Delete the new version’s deployment
and that’s it!
Canary deployment
Canary deployment is a method where the new version of the application rolls out incrementally to a subset of users as an initial test before being released to all users. The purpose of this method is to target a small number of users to collect performance metrics and predict the impact on users for a full deployment. After the group of users has used the application’s new version, metrics will be collected and analyzed to decide whether the version is production-ready and needs to be rolled out to the rest of the environment (or to the next phase), or whether it needs to be rolled back for further troubleshooting.
This strategy is best for cases when the results of the tests are not unequivocal, unreliable, or when the amount of traffic may affect the performance of the application.
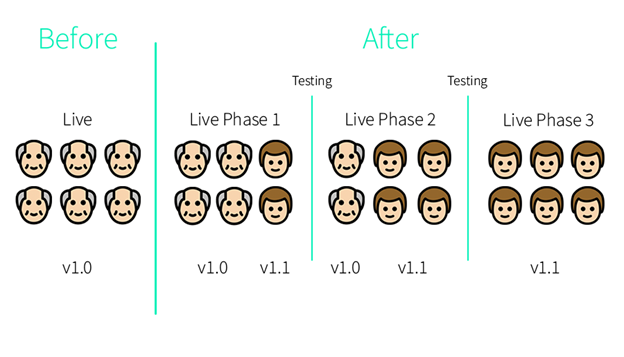
Canary deployment can be implemented in two-step or small phases (e.g., 5% of the users to 25% to 50%…), when a new application code is deployed, it’s exposed to several users.
This method has the lowest risk as compared to other strategies because of the control it provides.
You can define the exact percentage of the requests that will be forwarded to the new version at each stage, so if errors occur, only a small number of users will be affected and you can perform a quick and painless rollback.
For canary deployment to be successful, the performance metrics should be clear and both versions should be deployed in the same environment under the same conditions.
This method has the option to deploy a new version for a custom customer base. You can sort the users by their application experience level, geographic location, or usage frequency.
The goal of making a better application is always the same, but it’s important to think about what information you want to get from the Canary deployments, like choosing a subnet where trust is high or where the loss of customer trust will have a low impact.
One drawback of using canary deployments is that you have to manage multiple versions of your application at once. You can even have more than two versions running in production at the same time. However, it’s best to keep the number of versions running simultaneously to a minimum.
You can read more about rolling out different versions to different customer bases in this blog post by LaunchDarkly (who focuses on deployment solutions).
Why should I use this deployment strategy?
- I don’t want my users to experience any downtime
- The users’ experience is highly important to me and I want to minimize the chance of them encountering bugs while using the application. Even if bugs are discovered, only a small number of users will be affected
- The application’s traffic may affect the performance of the application
- My current infrastructure costs are high and I can’t use more resources
- I need some time to monitor the new version’s effects
Pros:
- Zero downtime
- Quick rollback
- Testing with real users and use cases
- Bugs will only affect a small number of users
- No additional infrastructure costs
Cons:
- Slow rollout speed
- Requires testing and monitoring each phase
- Not so easy to implement
- Not all users will experience the new version’s features immediately
To implement canary deployment:
There are many ways and tools to implement canary deployment. This is the most simple one to use without any additional tools.
- Deploy three instances of the first version of the application
kubectl apply -f version1-deployment.yml && kubectl rollout status -f version1-deployment.yml - Apply the production service
kubectl apply -f production-service.yml - Decrease the current version’s instances to 3
kubectl scale --replicas=3 -f version1-deployment.yml && kubectl rollout status -f version1-deployment.yml - Deploy the new version of the application on 3 instances
kubectl apply -f version2-deployment.yml && kubectl scale --replicas=3 -f version2-deployment.yml && kubectl rollout status -f version2-deployment.yml - Change the service to point to both versions when 3 instances are the current version and 3 are the new one. In other words, 50% of the users will access the new version and 50% will access the current one
kubectl patch service production-service --patch '{"spec": {"selector": {"version": null}}}' - # Run tests on the new version’s instances
-
- If issues were discovered in the new version during testing, Rollback to the previous version (Delete the new version’s deployment, and increase the previous version’s instance number to the original)
kubectl delete -f version2-deployment.yml && kubectl scale --replicas=6 -f version1-deployment.yml && kubectl rollout status -f version1-deployment.yml - If the version is functioning well, complete the rollout by deleting the current version’s deployment and increasing the new version’s instance number to the original
kubectl delete -f version1-deployment.yml && kubectl scale --replicas=6 -f version2-deployment.yml && kubectl rollout status -f version2-deployment.yml
- If issues were discovered in the new version during testing, Rollback to the previous version (Delete the new version’s deployment, and increase the previous version’s instance number to the original)
Canary deployment has its own challenges. One of the biggest hurdles is managing dependencies between services and components of different versions. In some cases, the new version components cannot interact well with old version components which are still part of our application and vice versa. So, mixing the communication between old and new versions isn’t so trivial. There are a couple of good solutions for this challenge, but we won’t discuss them here as this would take us out of the scope of this article.
To Sum Up
No matter if you want to deploy a new version of your application on a local Kubernetes cluster or a cloud environment, there are many ways to deploy it, and the best way to do it depends on your needs and infrastructure costs.
When releasing a version to development/staging environments, or when application performance issues may occur while running multiple versions in parallel, Recreate deployment is a good choice.
For production environment, when infrastructure costs are not a problem (as it requires double resource capacity), a Blue/Green deployment can be the best solution for you, but running proper tests on the new application is required.
If there is little confidence about the impact/stability of the software, you are worried about the user experience, or your application requires testing a new feature amongst a specific customer base that can be filtered (like geographic location or experience level), then you may want to use Canary deployment.
Related posts: