
In his excellent CPPCon 2019 talk titled “There Are No Zero-cost Abstractions”, Chandler Carruth describes abstractions and their associated costs. Abstractions have run time, build time, and human costs. He nicely explains how an effort to reduce run time costs by using arena allocators resulted in an increased cost in build time. As he correctly points out, compilation is essentially a distributed system with a high fan-out. How do you set up such a system in the first place? How do you do it efficiently? How do you create efficient parallel builds? To know the answers, read on…
If You Can’t Measure It, You Can’t Improve It
In which unit do you measure your build times? Seconds, minutes, or hours? A build that completes in seconds is the dream of every programmer. Just as the number of WTFs are the only effective code review metric ?, I would say the number of minutes you spend at the coffee machine – waiting for the build to complete – is a good metric to measure the build efficiency. I would like to keep it not more than 5 minutes. How would you go about achieving this? There are broadly two ways to achieve this:
- Micro Optimizations
- Macro Optimizations
Micro Optimizations for Faster Builds
While doing a build on the command line using MSBuild, you might have seen this message:
Building the projects in this solution one at a time. To enable parallel build, please add the “-m” switch.
MSBuild parallel compilation is enabled by using the -m switch. As a parameter, you can specify the maximum number of concurrent processes to build with. If the switch is not used, you get the above message and if you don’t specify a value while using the -m switch, MSBuild will use up to the number of processors on the computer.
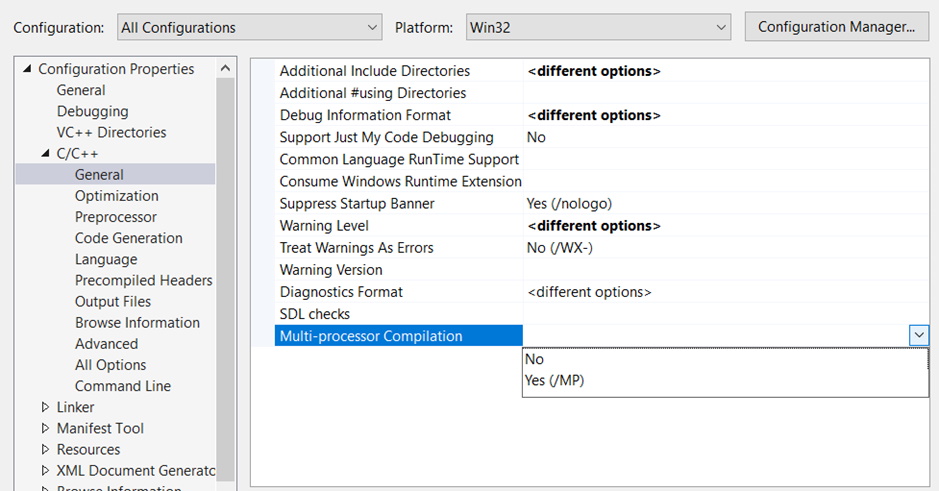
Visual Studio parallel build for C++ is a flag that you need to set in the configuration options. (Project Properties > C/C++ > General > Multi-processor compilation as shown below)
If you are using Make to build a target, remember to use the -j flag. This parameter allows multiple independent tasks to run parallelly thereby reducing the build time.
For CMake parallel build you can check out tip number 15 from this post about Modern CMake tips (DRY is a principle that I like to follow not just in Software Engineering you see.)
Using pre-compiled headers will greatly speed up the subsequent builds. During a compilation, every file is parsed and an abstract syntax tree is formed. This tree is an intermediate representation of the file parsed. A pre-compiled header file is also an intermediate representation for those header files which are rarely changed. As the name indicates, both parsing and compilation steps are not necessary for pre-compiled header files thereby reducing the project build time.
But there is a caveat. In a distributed build scenario, pre-compiled headers are not always a win as instead of building multiple units in parallel, pre-compiled headers aggregate the units thereby preventing task parallelism. Distributed builds without pre-compiled headers are faster if the pre-compiled header needs to be recompiled.
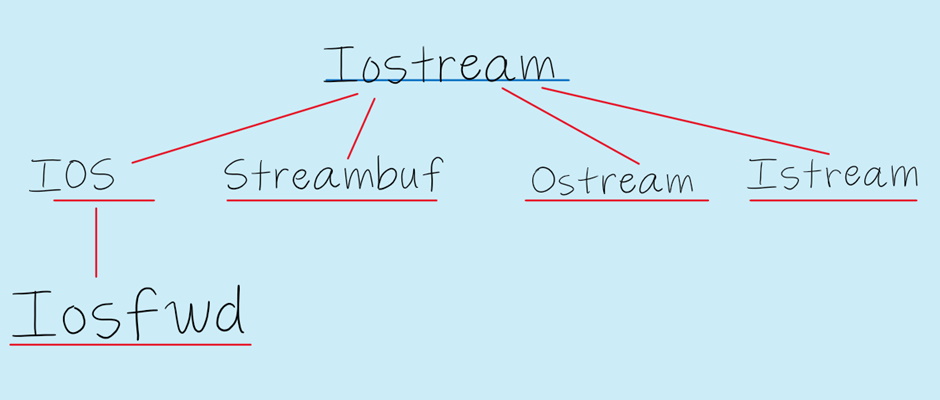
Try to make the dependency graph for every compile unit as small as possible. For a compilation unit, dependencies can come as class/struct references, function calls, API calls (standard system libraries, STL, third party libraries etc) coming through corresponding header files. When you include a common <iostream> header here is what you indirectly refer to:
Now let me tell you a little secret – there is an excellent tool that I use to reduce header dependencies which is called include-what-you-use (by the way, check out this post that discusses how to utilize include what you use). This was originally used for the Google source tree and is still in alpha state, but I have used it and found it to be excellent.
Let us say you have installed include-what-you-use in D:\Tools\IWYU, then here is how you use it in your CMake parallel build:
CMake -H. -Bbuild -DCMAKE_CXX_INCLUDE_WHAT_YOU_USE="D:\Tools\IWYU\include-what-you-use.exe;-Xiwyu;any;-Xiwyu;iwyu;-Xiwyu;--driver-mode=cl" -DCMAKE_C_INCLUDE_WHAT_YOU_USE="D:\Tools\IWYU\include-what-you-use.exe;-Xiwyu;any;-Xiwyu;iwyu;-Xiwyu;--driver-mode=cl" -G "Ninja"
(Ah, you don’t use CMake? Check out my blog posts for everything I have to say about CMake!)
This should give warnings of the form:
[2/72] Building CXX object CMakeFiles\mysecretproject\secret_vector_core.cpp.obj../secret_vector_core.cpp should add these lines:#include <corecrt_math.h> // for fabs, atan, sqrt#include <corecrt_search.h> // for qsort#include <vcruntime_string.h> // for memset#include <cmath> // for pow
../secret_vector_core.cpp should remove these lines:- #include <math.h> // lines 3-3- #include <iostream> // lines 7-7
The full include-list for ../secret_vector_core.cpp:#include <corecrt_math.h> // for fabs, atan, sqrt#include <corecrt_search.h> // for qsort#include <stdio.h> // for sprintf, NULL#include <stdlib.h> // for free, malloc#include <string.h> // for strlen, strncat#include <vcruntime_string.h> // for memset#include <cmath> // for pow---
Here are some tips on using include-what-you-use on windows:
- CMake has native support for include-what-you-use, but remember that if your source tree has both C and CPP files you need to specify both options CMAKE_CXX_INCLUDE_WHAT_YOU_USE and CMAKE_C_INCLUDE_WHAT_YOU_USE
- You need to specify –driver-mode=cl argument if you are building using Visual Studio compiler
- The generator needs to be Ninja as the default Visual Studio Generator for windows does not work for include-what-you-use
Macro Optimizations for Faster Builds
Before I describe any macro-optimizations for faster builds for C and C++ projects let me remind you that I am the CTO of Incredibuild and we are in the business of getting faster builds for our clients. We originally started with faster compilation time and now we accelerate not just compilations, but also testing, code analysis, simulations, and more, which lead to dramatically faster continuous integration cycles.
The first macro technique for a faster build is an extension to multi-processor compilation. Multi-processor compilation is limited to multiple processors in a single machine. What if we could use an army of networked computers to distribute the load? Tools like Incredibuild does just this. This technique should vastly improve performance.
A second macro technique for a faster build is to optimize each part of the continuous integration pipeline – be it Azure DevOps or Jenkins builds. Setting up Jenkins parallel builds is as simple as configuring a master node and at least two slave nodes. Adding distributed build capabilities to your Jenkins node (by using Incredibuild) transforms your build nodes to supercomputers with hundreds of cores that can be utilized using idle CPUs in the local network or by seamlessly scaling to additional resources in the public cloud. Multiple resources can be found on the Internet describing how to set up Jenkins parallel builds using both Jenkins declarative as well as imperative pipeline approach. But in most of the continuous integration builds, there are multiple steps involved like: checking out the branch, running some configuration checks, doing a CMake Configure and then a CMake build with even a quick smoke test included to make sure the build is used for quality assurance. You must optimize each stage of this pipeline such that your builds are available faster. In this regard, I urge you to check out my blog post about the shift left approach that describes this trend in more detail.
Conclusion
Setting up efficient builds for any language takes practice and planning. There should be technical leaders in any project who understands the value of optimizing such mundane tasks as builds which greatly impact developer productivity. Setting up efficient parallel builds is not trivial and if this becomes a bottleneck in your development setup, consider implementing distributed processing technology such as Incredibuild.
