
Tips from a VP R&D who also manages the software release management process
Knowledge comes from experience, as most of you would likely agree. Today, I’m a CTO, but I put in the legwork, starting my career as a software engineer before moving to manage both development/QA teams and the release management pipeline. Throughout my career, I’ve worked on hundreds of projects, some with poor software release processes—even no process at all—and others with well-defined release pipelines. In this blog post, I’d like to share with you some of the practices that may be harming your software release process. Don’t worry, I’m also going to let you in on how to get the release management process right. But first, let’s talk about software delivery.
Many applications today are web-based, meaning they’re either cloud compliant or cloud-native. But not all applications are appropriate for the cloud, and so a large portion of enterprise solutions are hybrid or on-premise deployments.
On another front, open-source packages are playing a major role in web development as well as in standalone applications. Automation has also become a must for many companies. And mobile is another important market, with many frameworks supporting mobile development.
Generally speaking, it’s a great time to be in the software industry. But what effect has this evolution had on software release management process? In terms of tooling, there has certainly been a huge positive impact:
- Many services today offer continuous integration and continuous delivery as a service, which eliminates the need to deal with underlying infrastructure and configuration and requires that only the pipeline steps be maintained.
- More open-source packages for CI/CD are available now than ever before. Jenkins, for example, can be used on-premises if there is no SaaS solution to fit your needs. Build and testing tools such as Cmake and the Google C++ Testing Framework can be used in the C++ ecosystem as well as C++ API for Selenium.
- General IT automation solutions like Ansible or infrastructure as code packages such as Terraform are also available.
- Services for supporting the release management process itself enable you to handle the entire process from a web application.
Sorry to be a party pooper, but despite this impressive progress, when it comes to the release management process efficiency, little has changed. For decades, we’ve been dealing with the same issues:
- Lack of communication and governance
- Failure to implement software engineering best practices
- Undisciplined teams.
These problems continue to pollute the software delivery process today, making it one of the greatest industry bottlenecks.
Room for Improvement…
So what are we doing wrong? Where can we improve? Well, it’s time to take a hard look in the mirror and reflect on your software delivery practices, which have likely been less than optimal. So let’s discuss some of the common mistakes to avoid in the delivery process.
We’ll start with the tech side and then discuss management issues separately, since each requires a different approach. The good news is, when it comes to the tech, these issues can generally be addressed immediately by working closely with your DevOps team, and improvements can be seen in the short to medium term. Management issues, on the other hand, where people and culture are involved, are often a lot harder to tackle and require a little more patience.
Tech Issue #1: An Unreliable CI/CD System

When your CI is reliable, this means it’s working efficiently. If your CI/CD system isn’t up at least 99.5% of the time (and hopefully 100%), this affects your market/company’s economy. Trust me, you don’t want to have to delay a release because the CI system is down. The cost of downtime is not something to take lightly. While a lot of us don’t realize this, CI/CD downtime is as bad as production downtime and should be treated the same. You should definitely view your CI/CD solution as another production environment (CI/CD as a product): Set SLOs (service level objectives) for it; plan regular maintenance; and, of course, test it!
Try to use small pipelines and make sure that your servers/nodes are well utilized—it’s pretty shameful if your tasks are pending in a pipeline and you have two idle servers.
These can all help you use the underlying infrastructure more efficiently. I was once unable to deliver the entire sprint’s work because our Jenkins master instance was malfunctioning, and exactly on the day of our release! But this situation could have easily been avoided with regular maintenance.

Tech Issue #2: Slow Builds
The old cliché “time is money” is so true! I only really began to understand this when working on a project with a team of six engineers who were sitting around, literally doing nothing while builds and deployments were happening. I don’t blame them; they were right! There’s not much to do when your CI/CD is going on and that “building” notification’s up. True, incremental builds (the whole purpose of CI), short local builds; and more are there to ease the symptoms; but they don’t solve the problem. Even with all of that, we’re still witnessing a large number of companies running only nightly builds.
I was once in a situation in which every build for a pull request was taking almost 40 minutes. If we had 20 pull requests on average for a sprint, that was almost 13 hours where we couldn’t work due to the slow speed of our CI/CD. And this was happening every two weeks. But that was a mild case. I know release managers that spend hours on a single build. Needless to say, the slower your builds are the lower your team’s productivity will be.
While there are techniques to speed up build times, they’re often time-consuming and require readjusting the code. In addition, the performance improvement is not always as dramatic as you may have hoped for. The easiest, most cost-efficient way to handle this issue is to utilize distributed processing solutions like Incredibuild – and trust me, I’m not just saying that because I work there. By distributing tasks across machines in your network or public cloud, Incredibuild helps to speed up the execution of these tasks.
Tech Issue #3: Lack of Automation
The year 2020 is here, but projects are still being deployed manually. Manual deployments are error-prone, make the project dependent on specific team members, and are time-consuming. Because of this, setting up an automated CI/CD pipeline should be your team’s top priority.
Manual deployments also affect delivery and your team’s capacity. Automation applies to acceptance and capacity tests as well. It’s no fun for your QA team to have to do manual regression every sprint. In general, you should automate as much as possible. With automation, I was able to move from one to four deployments a month. We were deploying a feature or bug fixes practically every week—all of them within regular working hours.
Tech Issue #4: Discrepancies Between Environments
Welcome to dependency hell. Why am I so optimistic, you ask? Dependencies by nature work on your local machine, but not on your CI/CD servers nor on your coworker’s machine. If you added a dependency and didn’t update the CI, then Huston, we have a problem. This issue that is often discussed is the bane of every release manager’s existence. Dependency management is a complex task, especially when it comes to legacy applications. Stick to specific dependency versions, and if possible, use containerized solutions. From my experience, I can tell you that every single project in which I was too lax with the dependencies version ended up failing at some point during the build time due to a dependency change.
Tech Issue #5: Broken Builds Due to Failing Tests
Covering complex parts of the application with unit and integration testing requires a lot of effort. But teams often prefer to skip flaky tests since they’re “random” or because they’re rushed and feel they don’t have the time or the prerequisites for it. Also, agile methodology encourages us to run partial testing (“test what changed”) in order to save time. But skipping too many of these tests is just bad practice. In my experience, on more than one occasion, these random failing tests hit in production. And they’re usually a symptom of a bigger problem.
This is a very simple but strict rule: No test can be skipped during the deployment phase; if they don’t pass, then there’s no deployment. And while you’re bound to piss off some of your R&D and product guys, in the long term, they’ll appreciate it. Even better though, you can avoid having to deal with their short-term frustration altogether by finding ways to speed up test development (Check out Incredibuild’s acceleration solution for testing). This would allow you to include all the tests you need. The goal here is to completely eliminate test-related broken builds and to use automation to minimize the chance of them being deployed in production.
Management Issue #1: No Metrics
You surely have metrics for production, but do you have metrics in place for your CI/CD workflow? How well do you know your delivery capacity? You should ask yourself these questions:
- How much time is being spent running tests?
- How many minutes per day is your CI working?
- How many green/red builds do you have per day?
- How do you know if your CI system is malfunctioning?
- How much time does it take to get a build into production?
- How much time on average does each step in the pipeline take?
- How many concurrent builds is your CI/CD supporting?
If you can’t answer these questions, you probably don’t know exactly how many changes you can deliver. It’s important to add metrics to the CI/CD, just as you do with your production environments. Here are a few metrics that have helped me over the years:
- Error rates for machines/containers for the infrastructure
- Number of green/red builds per day/developer
- Max builds per day
- Pipeline duration.
These may seem like aggressive metrics, but you’re not trying to point fingers at anyone for not delivering; you just want to “own” your metrics and know what to expect. When numbers change (and they do, trust me), you’ll immediately know that something went wrong with your CI/CD pipelines.
Apart from the CI/CD, for performance analytics, or what you should really call “productivity analytics,” I use the Incredibuild Enterprise dashboard. It lays out my entire builds and machines utilization map with important metrics, such as the number of builds executed, average build duration, build status, processing time (per machine), and machine usage.
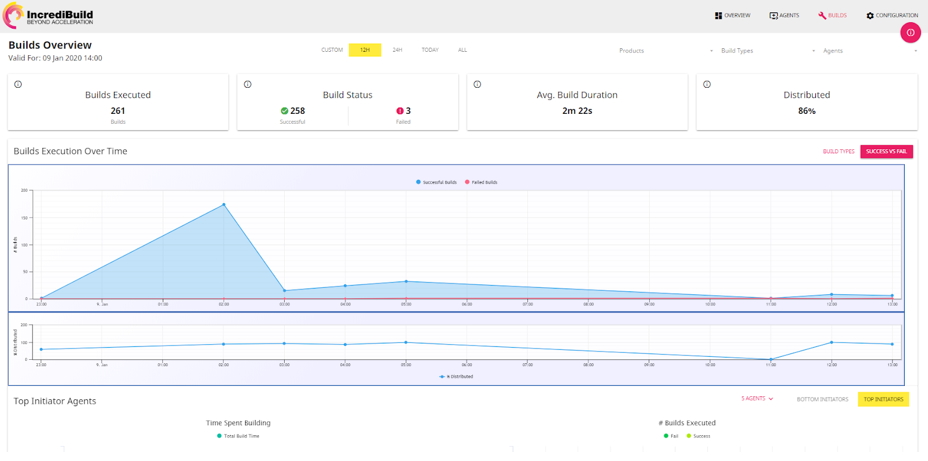
Figure 1: Incredibuild’s Enterprise dashboard
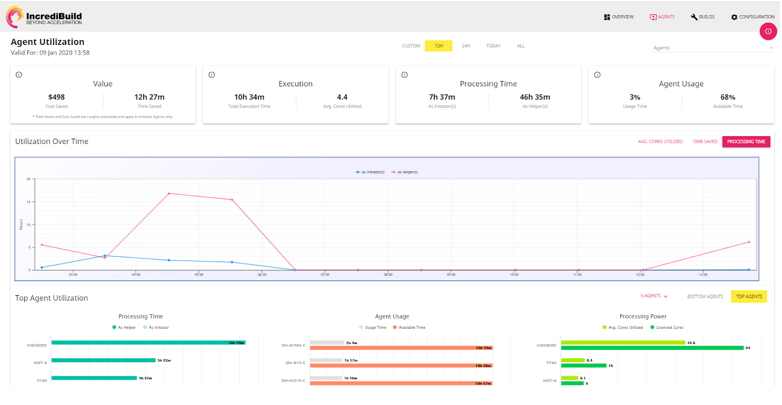
Figure 2: Incredibuild’s Enterprise dashboard
In addition, instead of missing all sorts of stuff using the regular output, I get my release managers to utilize build visualization tools, such as the Incredibuild build monitor tool. It enables them to monitor a build in real-time and retrospectively to see how it performed and how things transpired. Each color represents the status of the relevant build file, allowing you to identify which were built without any issues and those that require attention (e.g., tasks with long durations, errors, warnings, bottlenecks, dependencies, and gaps).
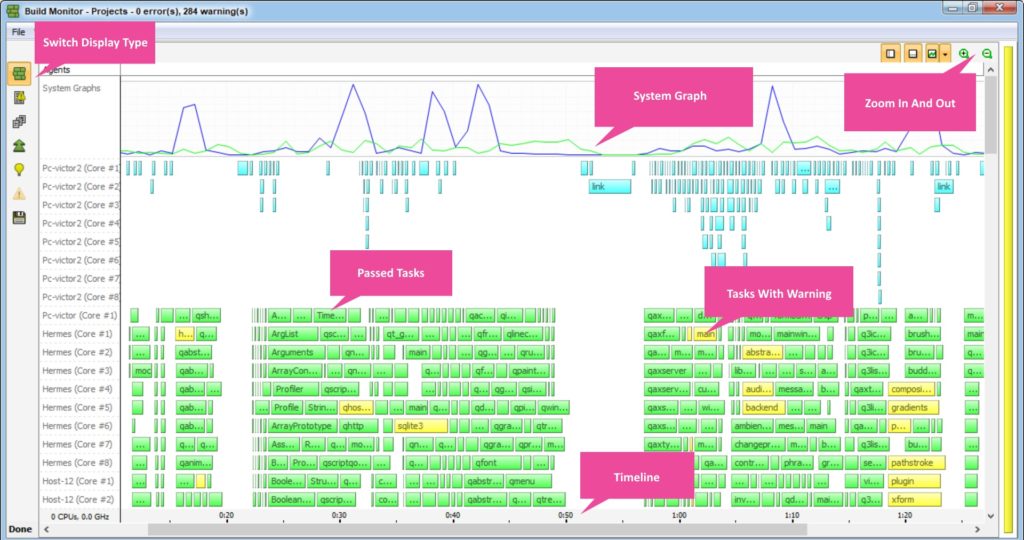
Figure 3: The Build monitor tool
The build monitor tool also allows you to monitor CPU Usage, tasks ready to be executed, memory usage, I/O, and much more.
Management Issue #2: Lack of Governance
Even with nifty metrics and the best tooling in place, if you don’t have clear, defined rules and procedures for the delivery, there’s no guarantee you’ll succeed (Let’s face it, success is never guaranteed, but there are ways to improve your chances). I would prefer to work on a project with a malfunctioning CI/CD system than one without release management process governance.
Governance is all about communication and accountability, and communication implies documentation. It’s extremely important to define the point of contact for a feature release and who should be notified when something’s being released. In fact, in my experience, a project should at the very least have:
- A documented release plan, including a release checklist template, a rollback procedure, and risk mitigation plan
- Documentation about your CI/CD infrastructure and how to deploy code (a detailed explanation of the pipelines)
- A shared release calendar
- Communication channels for notifying everyone involved that a new feature will be deployed and when.
I recall a project I was involved in for a big telecommunication company in which deployments were happening overnight (from midnight to six in the morning). The policy was to take turns performing deployments (deployment window). One night, one of the teams failed to report their progress, and nobody from any of the other teams knew whom to call for confirmation. Because of this, no other team was able to deploy. This could have easily been avoided with centralized documentation outlining who was responsible for each team’s deployment.
Final Notes
The software release management process is mainly recognized as a discipline within the spectrum of the software release process. Every project is unique, and the process for releasing code to production thus differs from project to project and from company to company. But there are still best practices that we as industry players (even leaders) should follow.
In this blog post, I shared some of the best practices I’ve learned from my many years’ experience in the field. While they’re all equally important in theory, in practice, some will be more relevant than others depending on the nature of the specific project. But for any project, working to achieve a “quality-first” culture within your team and enforcing this should be a top priority.
