
Security – an introduction
Security is an extremely important and deep topic. Bad things happen when security is compromised, and we have to keep that in mind at every stage of the software development life cycle. Unlike some other non-functional requirements, security cannot (usually) be baked into the system as an afterthought. ISO 9126, which describes quality attributes of a software system, names six major categories:
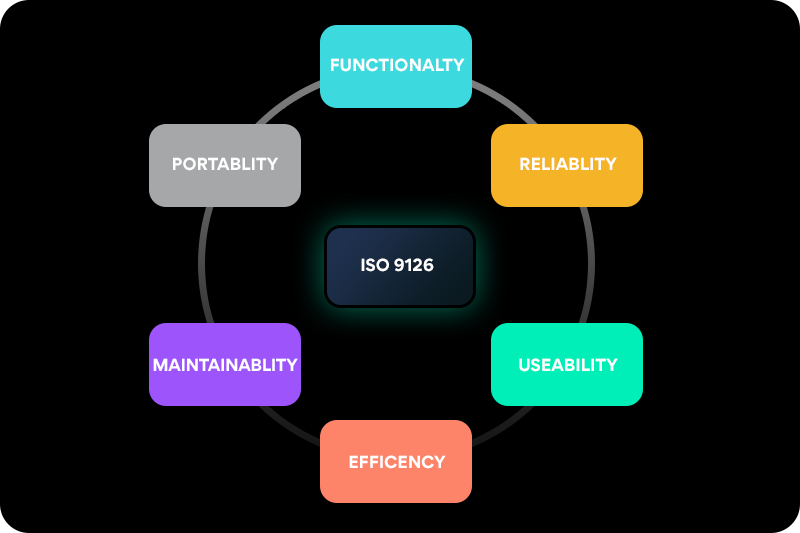
Security comes as a quality attribute under Functionality. Under security, we have quality attributes like Confidentiality, Integrity, Availability (together, famously known by the acronym CIA), Non-Repudiation, Authenticity, and Accountability.
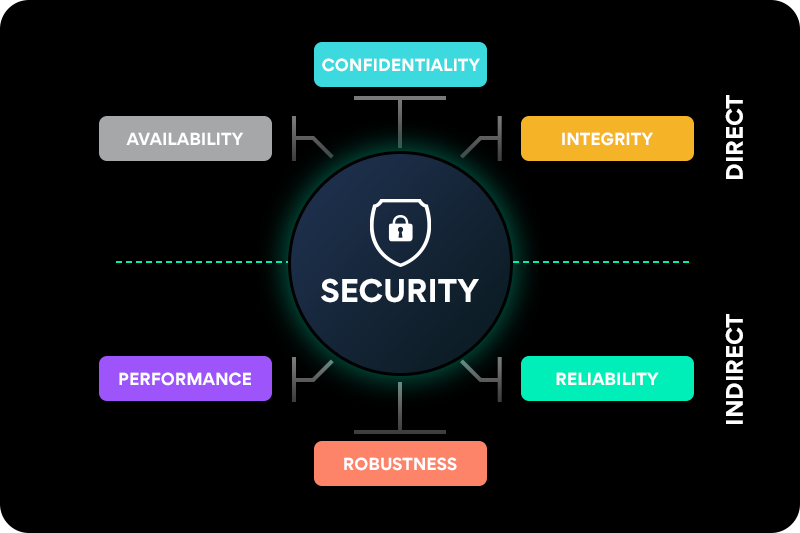
Security has a direct influence on its sub-attributes. This shouldn’t come as a surprise. What is surprising, though, is the effect of security on other quality attributes. For example, security has an indirect effect on performance and reliability. If the security of the system is compromised, the system may become unresponsive following a deliberate attack such as a denial-of-service (DoS) or distributed-denial-of-service (DDoS), or merely due to accidental high traffic that is not well managed and gets the service down. Similarly, if security is compromised, the system can become unreliable, spewing out unexpected results. Here is how I would depict it:
The current trend in security is Zero Trust Architecture where we apply the “never trust, always verify” paradigm to protect our system. We adhere to the secure by design paradigm once the architecture is in place. Only when both architecture and design are secure, we come to secure coding practices – the topic of this blog – and more specifically, top ten best practices in secure C++ development.
Let’s begin!
-
Understand that there are no safety nets provided by the compiler or runtime while coding in C++.
C++ compiler generates the code the programmer asked it to generate, without adding any safety checks. While coding in C# or Java, for example, incorrect array access would lead to a runtime exception, whereas in C++ this leads to incorrect memory access or memory corruption in case of writing. Incorrect or sloppy coding can lead to overflows (stack, heap, and buffer overflows) which can easily be used for an attack.
-
Don’t misuse APIs. Don’t rely on undocumented behavior. Don’t use APIs that are established to be vulnerable.
Depending on undocumented behavior is a doorway to security breaches that would arise if the actual behavior is not as assumed or has changed over time. This is explained in CWE (the community-based Common Weakness Enumeration) under item 440: expected behavior violation.
At the same time, it is highly advisable to refrain from using APIs that are well known to be vulnerable, including but not limited to strcpy, sprintf and system. It’s not that these functions are always unsecure, but used incautiously, they can be abused by an attacker. Static code analysis can usually detect and warn of bad usage of such APIs.
-
Validate input. Another classic.
There is no reason for anyone in 2022 to be writing oodles about input validation, but rest assured that if you trust the user with correct input, an attacker will find a way to breach the security of your application.This vulnerability is not specific for C++ but is of course also relevant to it. Input validation doesn’t only mean user input; in case your input comes from any source outside your system, it might be malformed. Even if it comes from another system that you do not control but consider reliable, the other system might have been penetrated and you don’t want to be relying on the security measures taken by any external system.
It is interesting to note that in the OWASP top ten vulnerabilities list, Unvalidated input was the number 1 threat in 2004. But since then two things happened: (a) the notion that input should be validated and sanitized has permeated into code review checklists and best practices, and (b) OWASP decided to rename this category, focusing on the security threat evolving from invalid data, creating a new category called “Injection” and moving some bad input vulnerabilities which are not related to “Injection” into other categories.

In the following years “Injection” was still high in the list (1st or 2nd), moving down to being number 3 in 2021.
Read more about techniques for input validation in the OWASP cheat sheet for input validation.

-
Type safety: Types are your friends. Don’t intentionally bypass type checking!
Gone are the days when we used passed around void*, bypassing type checking. Gone should also be the practice of casting to bypass strong type checking. Improper use of void* and casting can result in retrieval of bad data, which then can be exploited. Similarly, do not just downcast by reinterpret_cast or with C-style casting. Do not remove constness with const_cast or with C-style cast just because you need to and the compiler lets you. C-style casting, pointer casting and reinterpret_cast are generally risky and can be a source for exploitable bugs.
On the same note, though more as a best practice approach, it would be better working with strong types that carry with them their measurement units. You can read more about it here.
-
Be careful about arithmetic overflows or underflows in code.
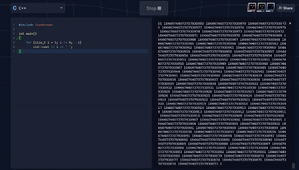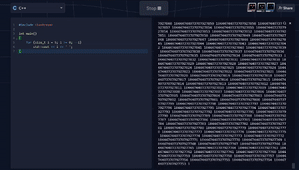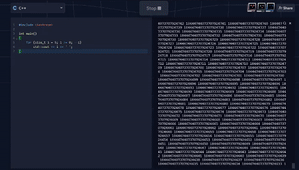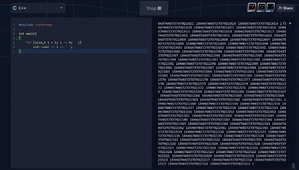
Trick question. Why is the code below:
#include <iostream> int main() { for (size_t i = 5; i >= 0; --i) std::cout << i << ' '; }behaving like this:

This is, of course, due to underflow, which occurs when the result of an operation is smaller than the allowed minimum value of the data type. This can lead to logical errors or execution of arbitrary code. Here is a real-world example from CWE – 190 (with some edits) of integer overflow:
The += operation can lead to overflow, which is undefined behavior for signed integers. This may result with an infinite loop or with any other bad behavior.
In general, avoid undefined behavior in your code. The first step should be to ask your compiler to warn you about undefined behavior in your code, with the -fsanitize=undefined flag, available both in Clang and in GCC.
-
Handle errors and exceptions carefully.
The program will not always follow the happy path. Anticipate the possibility of errors and exceptions. When they occur, enforce robust error and exception handling. How is this related to security? Careful error and exception handling entail:
- Not leaking sensitive information such as stack traces, database dumps, internal error codes, user IDs or any personal private information. An attacker can exploit them to compromise the system or just use sensitive personal information if revealed.
- Not allowing authentication into a system by triggering exceptions. This happens in a Fail-Open scenario where a system is open to use even when authentication has failed with an exception. An attacker can authenticate to a system by triggering an exception.
- Not just catching errors or exceptions and ignoring them, but also handling them. If an error return value is ignored or an exception is caught but not handled (“swallowing an exception”), then the system may continue to operate in an inconsistent state which may be vulnerable to attacks.
-
Don’t obsess over minor efficiency gains and jeopardize security.
Companies choose C++ (and C) to code systems that need to be highly efficient. Sometimes, in the name of efficiency, programmers are given free rein and end up jeopardizing security. An example might be not validating input for the sake of efficiency: “There is no reason to assume this variable will have invalid value, let’s get rid of this validity check” – well, even if there is a slight chance that an illegal value may get in, resulting with unexpected behavior, check!
Another example might be letting a variable or data member be born uninitialized, knowing that it would be initialized at a later point in code – basically, trying to avoid unnecessary initialization. This makes your code bug-prone, and if actually using the variable before it is being initialized – broken and unsafe. There are ways to avoid unnecessary initializations, but just waiving the initialization with the hope that the variable or data member would be initialized before use is not one of them. And as we said before, these kinds of potential bugs might be exploited, creating a security breach.
-
Implement security mechanisms correctly in the system.
One of the naïve ways of implementing security is through obscurity. Given enough time and resources, any obscure system can be hacked. Keeping passwords embedded in your code is a bad practice that should be avoided. Attackers can find passwords in binary files and exploit them. Even if you hide the password or obscure it – if done without proper care, hackers can still obtain it from your code.
Staying in the same domain, don’t implement homegrown cryptographic functions unless you’re an expert security researcher. While using cryptographic APIs from well-known libraries, make sure there are no known breaches or published compromises. Keep following this pattern throughout the lifetime of your code. If a breach is revealed in a cryptographic algorithm or library that you use, make sure to update your library and use the fixed version.
It is also to be noted that if your security mechanism is based on random numbers (e.g., users get a validation code in a two-phase-authentication), the basic simple random function in C++ is considered bad.
A compliant C++ solution for getting a random number shall use the new C++11 random generators, like in the code snippet below:
#include <random> #include <string> std::string getRandomId(size_t parts = 1) { static constexpr size_t max_size_t_dec_digits = std::numeric_limits<size_t>::digits10 + 1; static constexpr size_t max_parts = std::string().max_size() / (max_size_t_dec_digits + 1); parts = std::min(parts, max_parts) std::uniform_int_distribution<size_t> distribution(1, std::numeric_limits<size_t>::max()); std::random_device rd; std::mt19937_64 engine(rd()); std::string id; id.reserve(parts * (max_size_t_dec_digits + 1)); id += std::to_string(distribution(engine)); for(size_t i = 1; i < parts; ++i) { id += ('_' + std::to_string(distribution(engine))); } return id; }*The code above was amended following some good reddit comments in a reddit thread on this article. Note that the code is an example for how to use C++11 random API (e.g. to generate a random id) and not of how to use random numbers in a crypto library.
Even after using a good random generator, you can still use it badly. You can read more about How To Use A Random Number Generator Badly in order to avoid bad randomness of any kind.
In the end, if your random numbers are not random enough, you might as well use simple algorithms like this or that. However, don’t go with using uninitialized variable as your random generation technique, as this is undefined behavior.
-
Use C++ secure coding standard to complement your C++ coding standard.
You probably use C++ coding standards to get better code and to comply with C++ best practices. A counterpart that is often overlooked is C++ secure coding standards like SEI Cert C++ (you can browse it in PDF format or as html). The SEI Cert C++ standard is divided into rule categories which include: Declarations and Initialization (DCL), Expressions (EXP), Integers (INT), Containers (CTR), Characters and Strings (STR), Memory Management (MEM), Input Output (FIO), Exceptions and Error Handling (ERR), Object Oriented Programming (OOP), Concurrency (CON) and Miscellaneous (MSC). Not all items in the standard share the same security threat level, but the standard itself maps the security threat level per each item presenting the severity of the item and its likelihood.
-
Use the right tools to detect security issues.
Again, this is a generic tip applicable across many programming languages. The first tool at hand is your compiler: Compilation errors cannot be ignored, but warnings might be ignored, and they shouldn’t be.
The next tool that could help you is your compiler sanitizer. For Clang and GCC use the -fsanitize flag with its different options; for MSVC, read about its address sanitizer here. Use it! After we got all we can from the compiler, we need to use static code analysis tools that can help find additional issues in our code. Many static code analysis tools use CERT SEI and CWE lists as a source for security errors to look for. In some cases when a tool reports a detected issue it would actually point to the relevant CERT SEI Rule number or CWE Weakness ID.
As already mentioned, the threat level is not the same for all issues, and in some cases the static analysis tool may report an issue that would be analysed to be a false positive. So before rushing to change your code, check the reported issue carefully. Many static analysis tools offer an option for marking the reported issue as a non-issue, with a proper comment, so that the tool won’t report it again on the same code location. If you do that, make sure to properly document in the comment the reason for closing it and why it is a non-issue in this specific case.
Summary
Writing secure code that is not open for hacks and attacks is not a luxury. Any codebase must see security as a required feature of the system, even if the requirements forgot to mention security or left it with the known TBD.
It is the developers’ responsibility to make sure their code doesn’t infringe security. Security vulnerabilities arise due to bad design and faulty logic, or because of a bug, malfunction or potential breach that can be exploited.
Many of the coding practices mentioned above are generic enough to be applicable across programming languages. This is expected, as security is agnostic to the language in which the system is implemented. But there are issues specific to C++, especially concerning memory management, buffer overflows, casting and undefined behaviors of all sorts.
Remember during code reviews to check for security issues just as you check for functionality issues, and make sure to use the right tools that would help you pinpoint potential vulnerable code.
Postscript
While concluding this writeup, I came across “PrintNightmare”, a security vulnerability in the printer spooler of Microsoft Windows, disclosed on July 1, 2021. The vulnerability can be exploited for both remote code execution and elevation of privileges on almost all versions of Microsoft Windows. The root cause of the issue was pointing to a piece of Windows code which boils down to a particular function:
__int64 __fastcall SplAddPrinterDriverEx(LPCWSTR lpString1, unsigned int a2,
unsigned __int8* a3, unsigned int a4, __int64 a5, int a6, int a7)
{
// Do some initial work
int v11 = 0;
if (!_bittest((const int*)&a4, 0xFu)
v11 = a7;
if (v11 && !(unsigned int)ValidateObjectAccess(0i64, 1i64, 0i64)
// Do work …
}
The ValidateObjectAccess check can be bypassed by an operation that can be performed by the user, as the parameter a4 is based on the user environment. This leads to a critical vulnerability which Microsoft rushed to fix and release as a security patch. You can read more about the printer spooler breach here, here, and here.
That should remind you that security is to be considered very seriously!
