
Renowned futurist Ray Kurzweil is famous largely for how accurate his predictions are – of his 147 predictions in the past 30+ years, 86% have been spot on. That’s almost as good as the Simpsons! So, we can say he’s usually good at looking at where we’re going.
In 1999, Kurzweil predicted that by 2020, our phones would be as smart as we are. Was he right? Let’s break it down. On one hand, our phones are capable of image and speech recognition, auto-responding to conversations, and detecting fraud. They’re essentially compact super-computers processing massive amounts of data.
On the other hand, humans are still necessary to design, build, and program the software and chips necessary for machines to work. The interesting thing about Kurzweil’s prediction is that he underestimated how much we’d come to value our phones – even over other people. Don’t believe me? Let’s try a quick thought experiment. You’re at the mall, and you lose both your phone and your kid. Which do you look for first? That might be extreme; let’s look at something a little less drastic. How often do you check your phone while you’re driving? How often do you do it even if it increases your chances of having a fatal accident significantly?
There’s no silver bullet
The real question is, why haven’t we fulfilled Kurzweil’s prediction? Because, honestly, it’s not that simple. Fred Brooks’ influential 1987 paper, “No Silver Bullet – Essence and Accidents of Software Engineering”, posits that despite existing (and in his case, future) advancements, there’s no real way to reliably achieve the time, cost, and quality targets of any software project. Brooks was skeptical that we would ever find a sure-fire way to prevent software development from turning into an uncontrollable monster.
Let’s explore a little deeper, though. By essence, we mean how we understand the business logic of the system requirements. The accident part is all those things we can fix – either by better practices or better tools. Let’s focus on this latter aspect – how having better tools helps you reduce the number of accidents, and lets your team focus on the essence of development.
I like to think there are two things that haven’t changed in decades – Willie Nelson and developers waiting for their builds to be completed. Look at the XKCD comic below. At first sight, can you tell what hasn’t changed in nearly 20 years? The fact that, for most developers, this still rings true.

Recently, Incredibuild carried out a survey of over 300 managers across industries to find the biggest stressors and issues are for their dev cycles. Unsurprisingly (based on what we’re talking about), 96% of respondents said that build times increased for them in 2021, and over two-thirds said this was a major time waster. I would have guessed meetings were the top time waster, but I guess that’s why nobody asked me.
The myth of multitasking
The XKCD comic above is funny, but it also highlights a major issue for developers – context switching. When we have to wait a long time for a build or compilation to complete, we’ll simply switch to doing something else in parallel – another task, a ping pong tournament, chair jousting, you get the picture. We’ll alternate between coding and reading pull requests, answering a Slack message, or scrolling through Reddit.
The thought here is, well, it’s not so bad, I’m great at multitasking! Sorry to say, but you’re probably not. In fact, some studies have found that only 2.5% of people are actually doing multiple tasks at once. Usually, switching to a second task is a false economy; we’re much worse at multitasking than we think we are. We lose energy each time we need to stop and put our heads back into a different task. We’ll feel a lot more exhausted at the end of a day full of context shifting.
This ties closely into how long build times affect your CI pipelines. Delays in development result in text and branch compromise, which leads to a limited frequency of integrations (a key part of the continuous integration process). It also makes it hard to assert “who broke the build” and delays critical feedback to devs.
It also results in later access to testable builds and creates QA bottlenecks, which leads to higher defect risks. In turn, this leads to late releases, delayed hotfixes, and impacts further development.
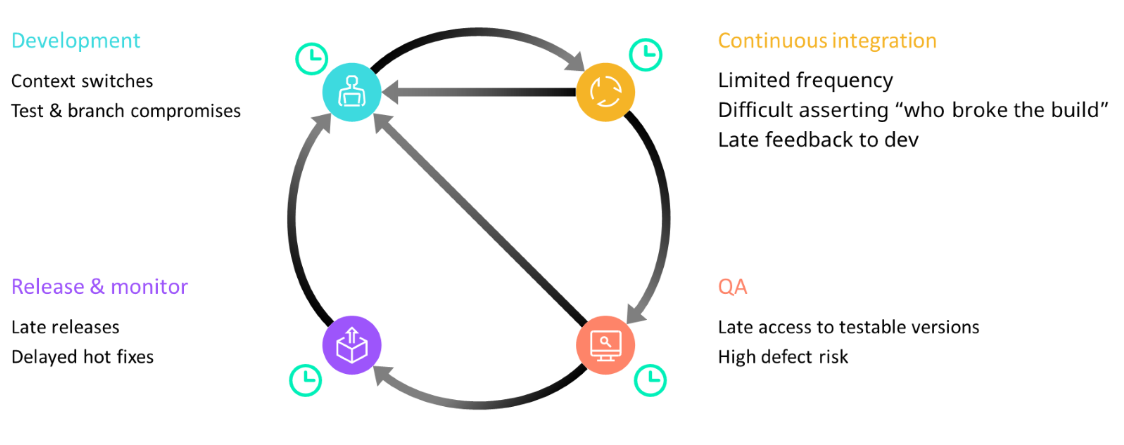
What are we left with? Poor quality, less creative solutions, poor developer experience, and ultimately a bad customer experience.
Everything, everywhere, all at once
Embedded software development can sometimes feel like you’re doing a million things at once. You need to be intimately familiar with your software’s target hardware, you need to think about connectivity, security, usability, and now also AI capabilities. And like we see above, we might be good with the “everything” part, but we’re definitely not great with “all at once”.
You know who can cover that part? SETI could. You might not remember this, but years ago, NASA asked people to install software on their PCs that would leverage their idle compute power when it wasn’t in use. The goal was to expand the capacity of their satellite and telescope systems to look for signs of life in space. Why am I bringing up something seemingly unrelated? Because that’s where the idea for Incredibuild (and how we distribute resource-heavy tasks) came from.
Rethinking dev acceleration
SETI used compute power and idle cores to boost their satellites’ reach, and dev acceleration uses the same concept, except to accelerate your embedded software builds. We do this in two ways.
The first is by dynamically distributing resources from a pool of compute cores exactly where they’re needed. Instead of having to request the right number manually, a dev acceleration solution will set the ideal number of cores for the right process.
Second, and perhaps more importantly, there’s more than just throwing compute power at a problem. Dev acceleration tools break down dev tools processes, reuse cached build outputs, and execute the rest in parallel across your network grid. In simpler terms, instead of having to do everything from scratch every time, one step at a time, you can take advantage of existing cached outputs to cut down on work. Furthermore, you don’t have to wait for linear builds to complete, you can distribute processes to actually multitask them and slash your wait times significantly.
Let’s take a little peek beneath the hood to break it down:
- When you start your first level CI parallelization starts, your acceleration platform kicks into gear – it intercepts your initiation and uses unique build cache technology to reuse cached outputs from earlier builds when input is unchanged.
- Then, it breaks down each dev process into micro-processes and distributes those in parallel dynamically across our managed resource pool.
And that’s it, really. Easy as that! If you want a bonus, breaking down tasks into the micro-process level also lets you get granular to gain even more visibility into your builds and identify any inefficiencies in the process.
Context switching – yesterday’s problem?
The goal of dev acceleration is – at its core – to make life easier across the board. Happy developers lead to happy companies, which lead to happy customers. Context switching will always be an issue for devs. After all, it’s not easy to stare at millions of lines of codes for indefinite periods of time. But the days of having to wait for builds to complete, of setting up intra-office ping pong tournaments or sword fighting across cubicles, might soon be in the background.
Think about it, why would you make your devs wait an hour for a build to finish – and potentially fail at 95%, forcing them to restart again – when you can cut it down to six minutes. That’s long enough to go get some coffee and come back, but not long enough to recreate a scene from The Princess Bride. In an ideal world, that XKCD cartoon will become a cute relic of past problems for the new generation of developers.