
Judging from the great turnout at our Virtual Round Table event on June 23, it seems that the problem of big code, referred to as “million lines of code (MLOC)”, is a topic that troubles many.
Just a recap for those of you who missed it: We sat down (virtually) with an impressive panel of experts to have an insightful discussion. Each and every member of this panel had an interesting angle to share, relying on years of experience dealing with million lines of code.
Our panel included the following experts: Titus Winters from Google (Senior Staff Software Engineer), Ed Keen from Red Hat (Sr. Mgr. Container Adoption), Marc Ullman from MathWorks (Sr. Systems Architect), David Schwartz from National Instruments (Chief Software Architect), and Incredibuild’s very own Amir Kirsh, Dev Advocate. I (Yohai West) was there to moderate and provide small nifty insights.
We all got together to discuss the various challenges concerning millions of lines of code and the ways to tackle these challenges (using tried and true optimization methods). We wrapped things up with a gaze at the future. Not all that was said is in here, for the full event:
Whose Problem Is It?
Let’s start with a few numbers to get the ball rolling. As it seems from Sourcegraph survey regarding the emergence of big code, almost everybody is affected by big code. This means that dealing with million lines of code is everybody’s problem. Check out the below charts – 94% of respondents, across all organizations and industries with no regard to their size or the specific number of developers, are affected by Big Code! By the way, not too long ago, Sourcegraph raised $50 million to tackle ‘big code’ problems with universal search.
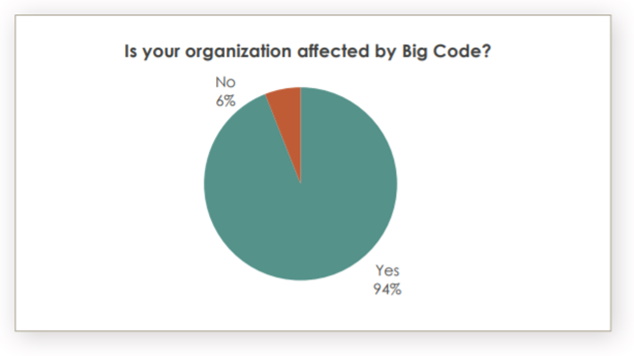
Image source: Sourcegraph
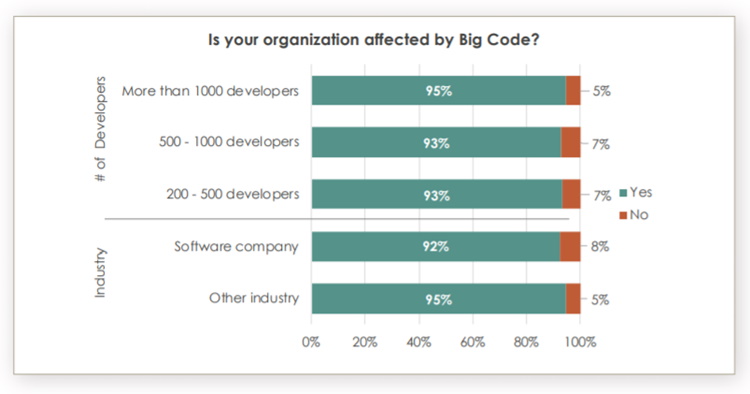
Image source: Sourcegraph
Now that we have established that Big Code is a widespread problem, let’s review the problematic aspect of millions of lines of code.
Why Is It a Problem at All?
Every time the topic of big code is mentioned, the conversation naturally turns toward the various challenges involved in maintaining and working with this massive amount of code. The saying “Big code, big problems” is not lost in this discussion. Here, as well, the Sourcegraph survey has an interesting take on some of the challenges:
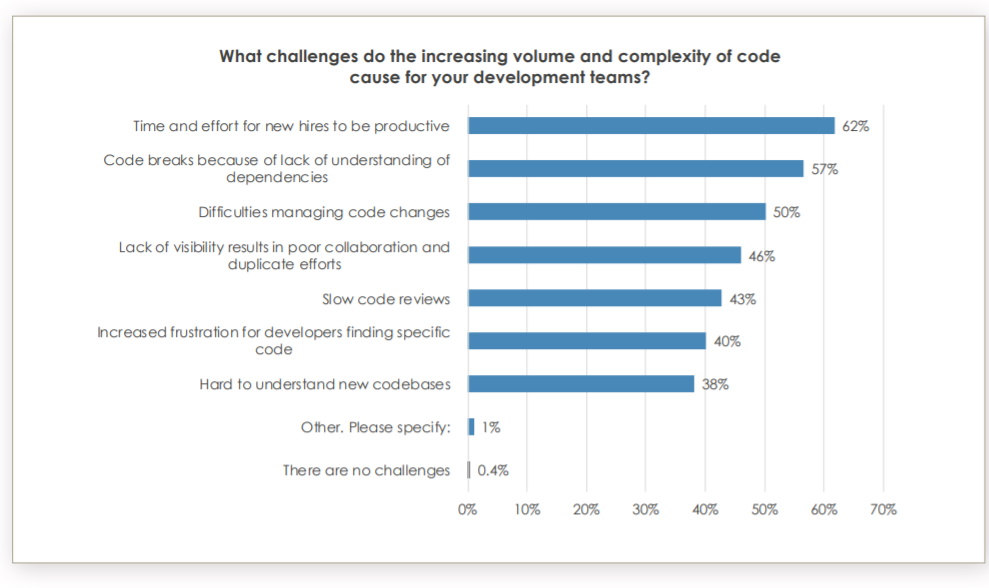
Image source: Sourcegraph
But we wanted our own take on the matter, so we’ve reached out to our pane asking:
“When we talk about millions of lines of code, what are the special challenges that are involved compared to smaller projects?”
Google’s Titus Winters, who oversees the C++ code base (about a quarter of a billion lines of code) was the perfect person to start with:
“I think once you start getting into the million plus lines domain, one of the things that’s going to be really important is looking at how you’re going to scale.”
He continued: “There are a lot of build systems, CI systems, version control policies, version control systems that are goanna start to have inherent issues. When I talk to companies that used to be small companies and now are medium-sized, but they’ve been around for a little while, they say the first thing that you do on day one is, before you sign the papers, turn on your machine and start pulling down a copy of the repo because it’s goanna take 12 hours. If you see that you’re gonna get up to this million plus world, it becomes so critical to think about every component that goes into that.”
One such component is the build system, as Titus describes it:
“You desperately need to invest in a real functional build system, by which I mean a build system with no side effects. The wonderful property that you get from a build system that is based on a functional programming language model instead of an imperative programming language model is you inherently have sandboxed every step of the build and therefore it is free to cache it and distribute it. Your build can be fast and reliable and reproducible. Once you have that you can build a CI that you actually trust [ …].”
Titus stressed the importance of starting at the fundamental levels:
“You have to start at these very low fundamental levels and so many people have just cobbled together something that sort of worked and they don’t ever realize that there’s a better world out there that is within a reasonable investment and that the improvement in developer experience is going to be magic. I cannot express how frustrated I am thinking back on jobs before I was at Google and just thinking about all the mysterious build problems and how much of the time I had to make clean. If you ever have to use make clean in your build system, your build system is bad. We’re goanna have to, as an industry, get to a better world, but it can be better.”
Marc Ullman from MathWorks (with an experience of 25 years’ worth of code accumulated by MathWorks, the creators of Matlab) further discusses the various challenges involved:
“It’s performance, it’s partitioning, it’s robustness, it strains the things that sit on top, and the underlying operating systems, and all the tools that tend to get strained as things get bigger, right down to CPUs – the amount of RAM it takes to debug something. Just basically everything gets harder as things get bigger.”
Dependencies as a Challenge
David Schwartz from National Instruments, who knows his way around millions of lines of code, focused on the well-known challenge of dependencies:
“When you end up with circular dependencies, if you ever get sucked into that nightmare, you will never be able to have a stable code base because someone changes something here and it breaks something there and then they fix it there and it comes back and breaks the other thing. If your code is too dependent on other parts of your code, it becomes almost impossible for anyone to get any work done. You can’t change anything in the shared modules without risking the entire platform and you don’t know which part you’re risking. I’m not saying it’s actually true. Of course, you know that the class I’m dealing which only affects this if you could do that, but how do you keep track of that for millions of lines of code? And the tools that you get from your compiler are helpful, but not so helpful.
David also brought up dependencies in relation to the build, a topic close to our heart:
“The other problem with dependencies is if you make a change and there are a lot of things dependent on, you have to build all of them in your validation build. I know, Incredibuild can help, but at the end of the day, building five million lines of code in a single build is not going to get done in the time of a coffee break, it’s going to take more like a lunch or more, especially if you’re running unit tests, and integration tests and so on, so it becomes much more difficult for programmers to work after a certain point in time unless you manage to keep a clear dependency graph and try to keep things a little bit more independent. That’s, I think, one of the reasons why microservices became such a popular buzzword because the idea was: my team works only on this little piece of code, and it has 100K lines of code – no big deal, it compiles in three minutes. If that works it’s great, but when you start breaking out and things start becoming dependent on other things it becomes much more difficult. How do you keep the independence between the parts and how you manage those dependencies between different parts, is really one of the biggest challenges.”
Titus took a bolder approach when it comes to dependencies, commenting on David’s observations:
“That sounds like you’re designing your system with fear. If you have sufficient unit tests […] and you make changes on hourly basis, it doesn’t matter because we can run all the unit tests for everyone, and yeah, some of those are flaky but we know how to read those, interpret those. You have to have signals to predict whether or not something is safe and then you just move on.
However, Titus agreed with David about keeping dependencies in order:
“I do think that you’re right in ‘don’t let your dependencies run wild’. There needs to be a layering, a cyclic-ness. You need to be pretty clear on what is a dependency that we intend everyone to use versus accidental coupling. […] But in the end, the idea of this only going to build over lunch […] again if you have the right sort of large infrastructure; distributed compilation, parallelization, caching, all of these things, this is all very, very doable. We just have to get out of the mindset that you’re going to build it on your desktop. Over time developers produce a lot of code and single machines are not going to do it. There’s a scaling mismatch between those things.
Preserving Conceptual Integrity
Stepping away from the dependencies’ discussion, Incredibuild’s developer advocate, Amir Kirsh, who obtained a vast amount of experience with big C++ code, briefly touched upon another interesting challenge:
“I think no one mentioned keeping conceptual integrity, maintaining documents, these are pretty difficult.”
Developer Experience

Ed Keen from Red Hat followed Amir’s challenge with one of his own:
“Another area that we haven’t really talked about is the developer experience. If you’re joining as a new developer on a team, the ramp-ups are obviously a lot longer. If you look at the alternative approach, taking a microservices-based approach, once you start getting into domain-driven design, people feel they’re closer to the business value so they really have a sense of ownership, where they start to see the impact that they can have on the business, so they’re ramping up quickly and there’s less churn as well. Whereas in the million lines code, with that long ramp-up time, trying to find whoever has the answers, whoever built this old thing that’s been around for a long time, you feel pretty crappy, like you’re wasting a lot of time and being inefficient. People don’t want to feel inefficient; they want to feel productive, and I think this is another thing that domain-driven design gives to people […].”
Managing and Keeping up With Design Documents
Amir mentioned the issue of managing documentation as part of preserving conceptual integrity. It seems there is a very cool way to tackle this challenge: docs within the code, as David described it:
“It was just an idea that got floated recently. I’ve actually seen some teams use it successfully where they create a directory within their git repository, and they created markdown files inside for whatever the high-level design is going to be. What’s nice about it is that you then commit that document into a branch, and you do a pull request and then you get the full pull request experience around your design […]. People can put comments into your document with what they think is a flaw in your design and then you can comment back and you can resolve those comments and that way the process gets kept inside that pull request permanently, which gives you not just the final document that you created, but it also a nice history of what happened and why it happened, what the considerations were, what the discussions were, what the different versions were along the way – until you get to the final thing. It doesn’t give you a nice wiki, which is what most people want to talk about documentation, but it is a nice process for designing documentation and it stays close to the code”.
Titus agreed:
“I think that was the biggest improvement in documentation health at Google in the last 10 years was moving docs to code exactly the way that was just described. It’s fabulous.”
But even with consistent documentation and docs within the code, it’s difficult keeping your documentation up to date. David addressed this challenge:
“It’s very difficult to keep your documentation aligned with what’s actually going on with your live code base, because people make changes to code and they don’t necessarily remember to make the changes to the documentation as well […]. It’s very difficult to enforce the accuracy of the documentation that you do, so it often falls behind. A lot of people prefer the code to document itself.”
Amir highlighted Wiki as a possible tactic to handle updating documentation:
“In some cases, not necessarily the design documents but some of the documents are maintained in a Wiki environment where anybody in the organization can maintain the document and then if there is a something which is not up to date anybody can come in and make the change”
“If they do it…” Titus followed Amir, “the trick is not, can you? Wikis are great if someone does it.”
Microservices as a Way to Handle Big Code
We spoke about a lot of challenges, but what about solutions?
ITProToday wrote a great piece about big code, bringing up the subject of microservices as a way to handle big code: “Although microservices and big code are rarely discussed in tandem, I have a suspicion that part of the reason microservices have become so popular over the past decade is that they help make big code more manageable.”
We decided to approach our panel and find out how do they feel the topics of microservices and big code interact; do these two topics conflict? Is there a dissonance? How do these two worlds resonate with one another?
Marc opened this discussion, suggesting that microservices for big code come with a cost:
“As with most things, there’s a balance and so certainly we continue to try to leverage microservices and other forms of modularity, but they actually come with a cost: When you have a really large code base you have lots of microservices, especially if those are like C++ microservices, as opposed to the classic separate processes microservice. That’s when you’re loading lots of things dynamically and you start to run into limitations, believe it or not, at the OS level. So, for instance, we found that our load times on the mac were very slow as we got bigger and bigger […] we’re seeing the same problem now with Linux […] breaking things up is a good thing but it comes with a cost when you start to put pressure on the underlying infrastructure.”
David talked about the human perception limit as a motivation behind any kind of modularity, such as microservices:
“The motivation behind going to any kind of modularity, but specifically microservices, is the fact that people can’t keep too many things in their mind at once. Known as Miller’s law, it’s a classic psychological principle that a person is only capable of holding in their working memory seven plus or minus two things at the same time. The idea of microservices is to isolate things so you’re not dealing with a million lines of code anymore – you’re dealing with a much smaller piece of your application, which stands by itself usually”.
However, David emphasized how these microservices are implemented and the importance of drawing clear lines between them:
“If you don’t draw them well, what you end up having is all these different microservices which are all talking to each other, and then they’re not really separated […]. You can’t work with a huge code base that’s broken into tiny services, all of which are dependent on each other. You’ve just basically taken microservices and turned them into a distributed monolith, and that makes it even worse than a regular monolith […]. It’s really an art form knowing how big or small to make each of those microservices and where to draw the lines.”
Titus pointed out where do microservices make sense:
“The important thing to keep in mind is microservices are good for limiting failure domains. In case there’s a bug, a crash, or a problem microservices are very good for it. They are very good if you have stateless components, subcomponents, services. The microservice model is going to be a whole lot better at how you scale that up. The more subcomponents within your monolithic distributed system that are stateless, the better you spin up additional copies of all those things with relatively little conceptual overhead. The question – as with everything – is how complicated it is to push quickly and reliably, how many humans you are going to have to coordinate with, how risky is a push, how is this going to scale? It’s the same as everything in software, the only really interesting questions are how does this work overtime, and how does this work as you scale up in terms of more usage or more teams contributing?”
Also, Titus addressed the relationship between a large codebase and microservices:
“I don’t think that microservices in any way really in conflict with a large codebase sort of problem. You can have multiple projects that are working in the same code base and in fact, you probably should, at least in my view, because then everyone is building on the same infrastructure, and you can have specialization and get all of the benefits of economies of scale. I don’t see the tension between those things.”
Who Are the Stakeholders of Big Code?
We thought it was interesting to discuss the stakeholders of million lines of code. What is their focus?
From his experience in filling a previous role as chief programming officer at Comverse, Amir answered:
“I can tell a bit about the role as chief programmer. It’s two-fold, it’s enforcement and advisory. For the enforcement part, you want people to use the same infrastructure, a narrow list of programming languages. You do not want the product to have a new programming language because some programmers decided to write this module with another new thing that they just found. Even if it is a great programming language, it should be maintained later on by the teams. You want to have a very clear baseline for what are the operating systems and versions to be used, so this part would be enforced.
On the other hand there are things that you want to advise, because you cannot, in a way, dictate for the teams how to do many things; but if you come up with advice and in some cases, a boost, you say ‘okay I advise you to do that, and we have some infrastructure to help you do it’ so you can influence the way things are being done and at the end you want to preserve conceptual integrity. You want people to be able to come from this part of the product to another part or to another product and see things work in a similar way.”
Titus followed Amir’s lead:
“I completely agree with what you said. Counterintuitively, the larger your company gets the more you need to not give people or not give developers options, like use a narrow set of languages that you have good infrastructure for, that is well supported, that you can centrally upgrade the compiler, instead of hundreds of teams having to do that once every five years. You’re going to get better consistency, fewer bugs, more performance – all those things the more that you can centralize in a lot of cases the better, so that people can spend the time focusing on product decisions instead of infrastructure ones.”
Waterfall or Agile?

It seems that agile is everywhere these days… or is it? We asked the panel: Are we doing agile? Is waterfall dead? Is it unnecessary? Is it a must for million lines of code projects?
Marc presented how things are done at Mathworks:
“Mathworks was founded as a company that targeted the control system market, and the common approach and controls is what we call successive loop closure: you have outer loops that are doing things like navigation and you have inner loops that are doing things like keeping the wings level on an aircraft. So you actually need both systems, you need some form of global navigation that’s giving you your trending and pointing you where you’re going, and then agile is great for those tight inner loops where teams are working on a high frequency loop of doing the actual work and responding to things as they come up.”
Ed talked a little about teams that are just now taking their first steps with agile:
“I was talking to a team a couple weeks ago who are now getting mandated to move to this ‘new agile thing’. I was like ‘only now and you’re referring to it as new?’, so it’s pretty stunning what you’ll still see out there and the knowledge gap as to what agile means and different ways of doing it and how to be successful with it. It’s not all unicorns and rainbows”
Chasing the Main Branch
Chasing the main branch is a common problem, and with large projects and large teams, it gets even more common and complicated. David commented on this topic:
“It’s a matter of taste. I personally don’t like branches that live more than a couple of days. Chasing the master happens because you don’t commit your code, you’re aiming too big and it’s a fallacy that programmers think that they can do a whole bunch of things all at once. Let’s do one small thing and get it in […]. Don’t try to do it all in one big check-in that has 15,000 files in it, you’re not going to do it well and you’re going to end up colliding on merges and then you’re going to make a mistake. It’s much easier to work on small things. I try to push all the developers I work with to check in within 24 hours […].”
Amir jumped in:
“The keyword here would be refactoring. Do the proper refactoring in order to bring the big thing easily rather than doing the refactoring with the new feature together, which would become chasing the main branch.”
Ending With a Note for the Future
To close off our discussion on millions of lines of code, we wanted to touch on the topic of the future. Are we preparing the next generation of our college grads to be able to come out and face the reality of million lines of code projects?
Titus had some thoughts about that:
“We don’t teach people how to read code, we don’t teach people how to be on a team, we don’t teach people that the job they’re goanna have in the industry is probably not one of: sit down and write a ton of code; it’s going to be: sit down and understand a ton of code and talk to five people and figure out like where to make a small change. What we prepare grads for is programming, which is not software engineering. I don’t know that we can do a lot better. It’s very hard to get those practical and collaborative skills in the relatively sterile environment that is a university program. I think the tension there is going to be very difficult but in practice, I think, they’re always going to be some challenging ramp up, especially for new grads entering a professional environment.
Ed brought up boot camps as a possible way to learn the ropes:
“I haven’t done one, but I’ve had some friends’ kids do these coding boot camps for three, six months and in what they tell me they learn a lot of the agile practices, they learn a lot about working as a team.”
Titus was a bit pessimistic about boot camps managing to teach the younger generation how to handle the reality of programming:
“I’m still a little worried. Even in a coding boot camp environment, you’re going to be working in a team that is not how any other team is ever going to work. How rare is it to have a team that is formed with no prior basis and everyone on the team is new? That’s not how things work. You’re going to have a mix of seniority. You’re going to have iteration […]. I think there’s a lot to be said for the coding boot camp thing in terms of it is a little less focused on assessment and a little less focused on theory and a little bit more focused on teamwork and practice. There’s a lot to be said for that. I think we need both, but even then, there’s still going to be a meaningful gap between that and what you actually need day one”
Marc followed:
“What we find very helpful is internships where students can come in (and you have one at Google as well) and get experience working with a large company seeing what the practices are and how things are done. Unless you’re in a graduate program where you’re working on a project that as you say has history, you’re just not going to get that in a university environment and so there’s no substitute for doing”
Amir emphasized the importance of reading code:
“What comes before a large codebase is reading code. Titus just mentioned that, and I must say that I’m giving my students to read much more code than I used to before. Reading code is very important. Not only writing new things but amending code […]. So, this is something that can be done preparing them for a million lines of code.”
Wrapping things up, Amir added:
“We always promise the future generation that things would be easier for them and I’m not sure this is the truth. Things would probably be more complex”.
For the full recorded webinar, click here.
Also, stay tuned for our community around million lines of code projects.
