
Once upon a time, in a world where C++ was young and the global codebase was small, it may have been easy to read and review one’s code, then adopt it and build the project out to infinity. Then again, that was probably never the case, but it is interesting to imagine a time when programs were short and simple, yet complete to the point where the functionality didn’t have to be extended. In such a world, code refactoring may not have been necessary. However, if a codebase ever needs to be inspected or updated, whether it’s being extended, improved to keep up with changes to the language, or even just reviewed to audit the efficiency, then code refactoring is more a necessity than just a nice thing to do.
The idea behind code refactoring is to make improvements to existing code without changing what it does. Essentially, the design and overall readability are enhanced, whereas functionality remains intact. The benefits of code refactoring are improved efficiency, readability, maintainability, and extensibility. Oh, and let’s throw in the extra of reduced complexity to top it off, both syntactically and semantically.
Why Is Refactoring Important?
The goal of refactoring is to make code more maintainable. By improving the readability, troubleshooting and debugging become easier. It also takes a lot of the guesswork away from newcomers tasked with adding new features, porting it to another platform, or adopting the latest and greatest features of the language.
It is important to remember that as novel functionality is added, cohesion decreases. Cohesion refers to how well the components of a module relate to one another, and in general, functions should be highly cohesive. Adding a new feature can boost versatility but rather than having a function or class that is highly focused, it is more broad and unfocused. One of the goals of refactoring is to increase cohesion.
Although code refactoring is not strictly intended to squash bugs, it has indeed led to the discovery of them. When near-identical code blocks differ only slightly, for example, the subtle differences are not always as intentional as they are copy-and-paste errors. Code refactoring is a fantastic step in preventative maintenance, helping to make legacy functionality clear for future developers.
Another important need for refactoring is preparing the code base for new functionality. When we need to add a new feature, a good way to do that is to first make all of the required changes in the code that would facilitate the introduction of the new feature, without changing the actual behavior. Thus, we can check regression, making sure that the code is ready for the new feature, yet still functions correctly. Next, we introduce the new functionality. This may require changes to the old tests, as the system behavior may change with the new functionality. Refactoring the code as the first step effectively narrows the risks that come with the expansion of the functionality.
When Should We Refactor?
Ideally, refactoring is done prior to building out an existing codebase. On the other hand, perhaps you want to modernize a legacy C++ codebase. In any case, when you’re approaching code intending to add new features or update existing functionality, it presents a great opportunity to clean up what’s already there. In particular, for those unfamiliar with the project, it makes for a good time to learn about what’s already in place. The refactoring effort will not only improve the project, at the very least in terms of readability, but it will make things easier for developers-to-come when the next set of enhancements need to be made.
Code Smell
The term code smell refers to something quick to spot that usually corresponds to a deeper problem in the code. It is important to remember, however, that code smell is usually an indicator of a problem, as opposed to the problem itself. Furthermore, it does not always indicate a problem at all. A good example of this is having a particularly long function. It may look suspicious and, ultimately, point to an area where subtle bugs lurk. That said, having a long function in and of itself is not an error.
There is another school of thought that suggests whenever a programmer sees an opportunity to make improvements, they should refactor. Hence, when they sniff a problem, just act on it. In fact, some suggest that it should not be a planned task but rather, something that is done routinely to ensure that the current codebase is always in good shape. The thinking is that if small refactoring tasks are done regularly then there is no need to schedule time for a more intentional and definite refactoring project.
When Shouldn’t We Refactor?
With so many benefits that come from well-done code refactoring, are there times when it’s best to just forgo the process? Certainly, there are situations where the time and effort required would lead to problems with deadlines. Code refactoring can be very time-consuming, and in some cases, large blocks have to be done before you can move to the next step. When deadlines are tight, code refactoring may indeed have diminishing returns and in the worst case, push you past the timeline’s breaking point. This is a costly mistake that can be avoided by proper scheduling. The bottom line is that refactoring might take longer than you think, so plan accordingly.
In the previous instance, it was a case of leaving well enough alone until there is a decent window of time available to operate. However, sometimes it is prudent to skip refactoring for the opposite reason. I’m talking about cases where you can’t just leave it alone. Specifically, the code needs to be significantly updated, and a full re-write may be in order. There comes a point where code refactoring is simply less efficient than starting from scratch.
Why Is It Hard to Do Refactoring in C++?
There is an inherent set of problems associated with refactoring a codebase. For example, if the team is not familiar with the current state of the system or the design decisions that were made to this point, it will take time to get up to speed. The developers must have an understanding of the functionality to ensure that they don’t disrupt it. For example, trying to modernize a codebase without having the requisite knowledge could easily introduce a subtle bug that is difficult to catch without extensive testing.
Aside from the problems that could affect any language, C++ developers find code refactoring more challenging, in part because the language is complex. This complexity is compounded with language-extending functionality such as macros and templates, not to mention that the language is large, to begin with, and the syntax is difficult to process.
Luckily, there are some very good basic refactoring steps that you can follow, and some IDEs can be of assistance with their refactoring tools.
Some Ides Include Refactoring Tools
Several IDEs support refactoring, at least to some degree. While not every IDE will handle all of the steps in the process, the feature will no doubt help to save time in development and testing. When comparing modern IDEs such as Visual Studio and Eclipse, it is clear that both have code refactoring capabilities. Some are built-in, whereas more advanced refactoring capabilities are available through the use of extensions. Also included in our list of Best C++ IDEs is CLion by JetBrains, which includes several automatic refactoring features.
Visual Studio, for example, has several built-in refactoring actions available for C++, many of which are available from the Quick Action context menu. If more functionality is needed, then the Visual Studio Marketplace has myriad extensions available to help. A popular extension for Visual Studio is Visual Assist, by Whole Tomato Software. This provides a variety of functions to assist programmers, including more advanced refactoring techniques.
Top Techniques for C++ Refactoring
Refactoring is clearly a worthwhile exercise, provided that it is done at the right time. Also, refactoring is sometimes better thought of as a series of micro-refactorings, where each is a small set of changes in the source code. These small changes bring about obvious benefits and to best take advantage of them, we suggest the top techniques are renaming, extracting, inlining, and moving objects. A valuable resource on the topic is the well-known book, Refactoring, by Martin Fowler, with Kent Beck.
Renaming
When it comes to picking names, a lot of people get it wrong the first time around. It may have been lazily or inappropriately named right from inception, or perhaps, the functionality has evolved to the point where the name is no longer an accurate description. Thankfully, making this type of change to a class, variable, or function isn’t as difficult as it is with a birth certificate.
This operation can be as simple as using a standard text editor to copy and replace the specific names, although when it comes to C++ and coding in general, the scope is important. Are the changes intended to be made globally, or is it something quite specific to a function or class? Visual Studio offers the Rename function, which is illustrated by the following example.
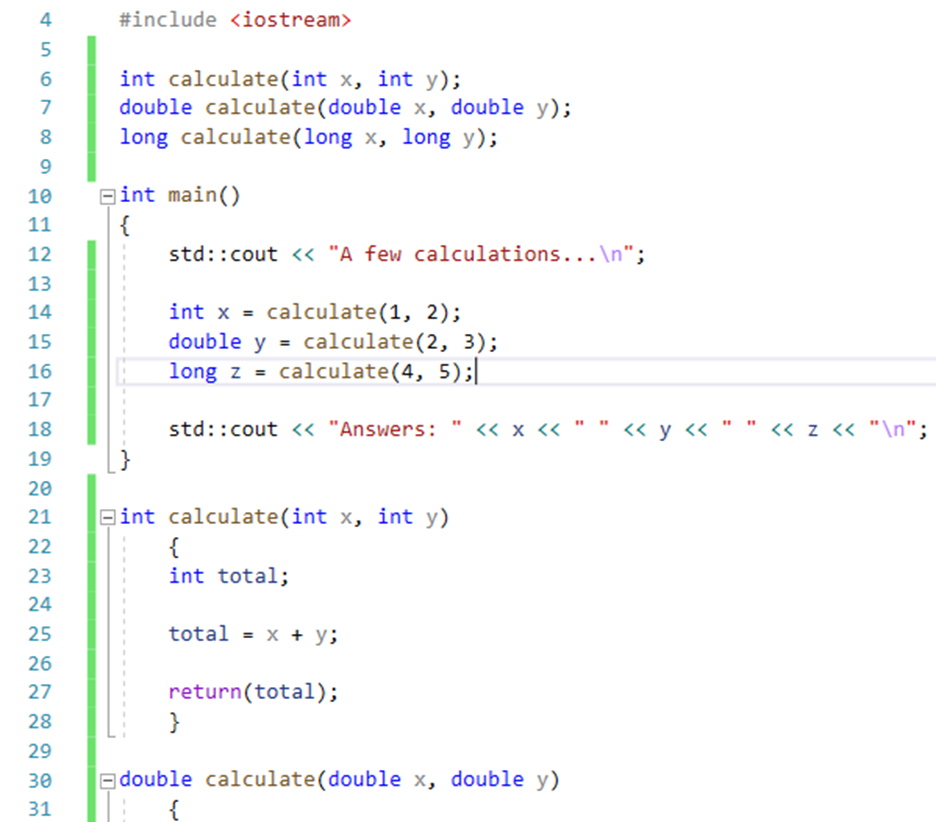
Figure 1: Trivial code base with general “calculate(…)” function
Right-clicking on “calculate” brings up the context menu, with an option for Rename. Once it is selected, it will bring up the options for renaming the entity.
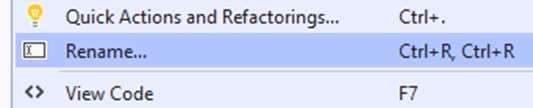
Figure 2: Rename is available from the context menu in Visual Studio
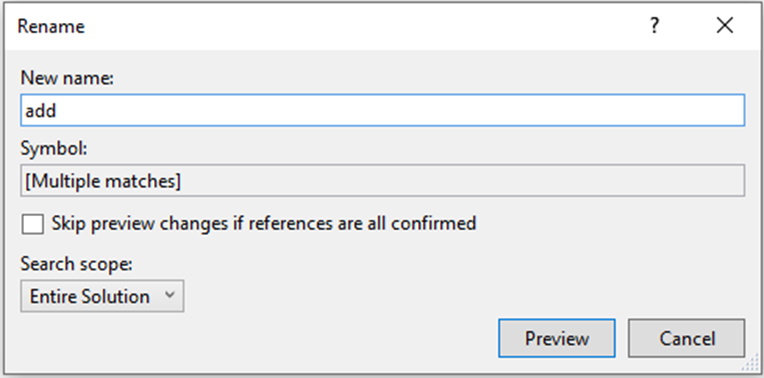
Figure 3: Options for renaming a variable in Visual Studio
Once the “calculate” has been replaced by “add”, taking the scope and the other options into account, the result is a more aptly named variable used throughout the entire program.

Figure 4: Trivial codebase, post-Rename operation
Notice that the code is just a couple of lines longer than it was originally. This is because the simple Rename method took it upon itself to add the “int main();” declaration at line 6. As the prototype for main doesn’t particularly help, this is a good example of where automatic refactoring could have unintended side effects. Not all automatic refactoring steps made by the tool are optimal and as such, the programmer may choose to override them in the interest of simplicity.
Extracting
Extracting can be done on variables, functions, classes, and even parameters. Essentially, it involves splitting up code into smaller and more discrete chunks, akin to building blocks.
Function Extraction
In the following example, a near-identical loop is used to increment two different values. Different approaches can be employed using Visual Studio’s built-in function extraction. This example deals with the first of the two loops, where a new function “incrementLong(…)” is created. This more generic function is instead called twice, instead of running two different for() loops. Although nothing is going to change in this trivial example, a more complex procedure would benefit because inner-loop changes only need to be made once.
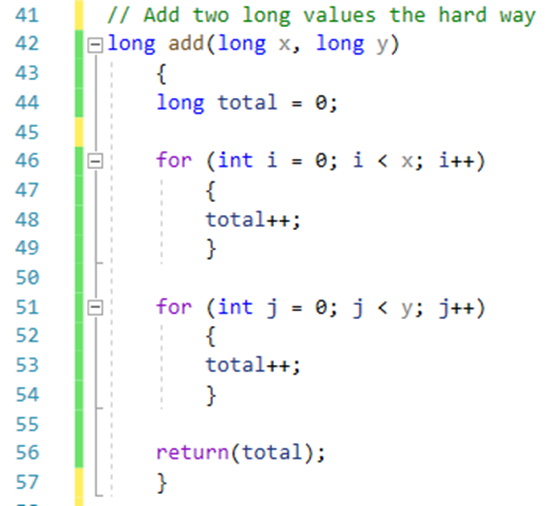
Figure 5: Toy function with duplicate loops used for adding two long values
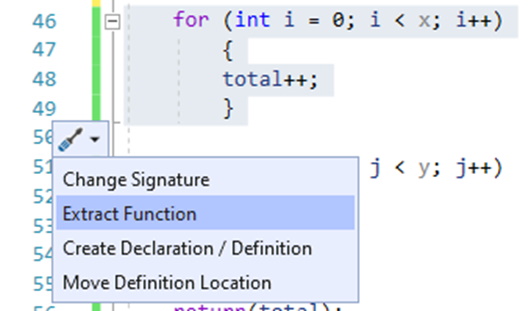
Figure 6: Using Visual Studio to extract the loop to its own function
Once the code is selected for function extraction, the developer is presented with a small number of options, along with a preview of the new function’s signature.
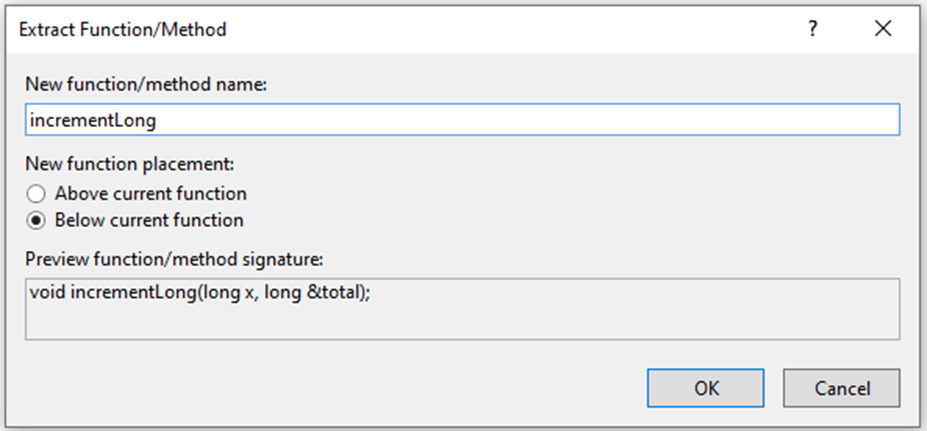
Figure 7: Extract Function options in Visual Studio
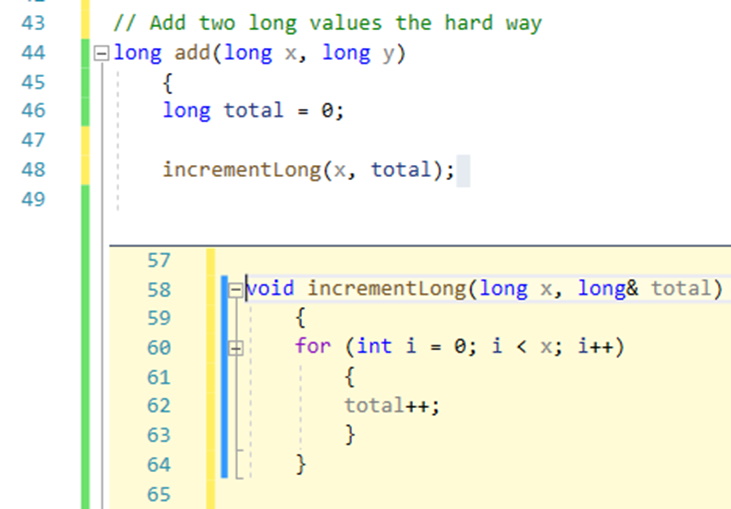
Figure 8: Single function extraction in Visual Studio
Variable Extraction
If you understand that function extraction is used to consolidate and discretize code, then you understand what happens with variables and classes, as well. Variable extraction is used to create a variable out of an expression for the benefit of code readability. Consider the following example:

Figure 9: Pre-variable extraction
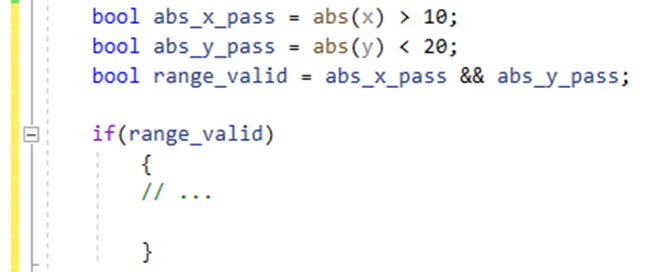
Figure 10: Post-variable extraction
Although there is the obvious trade-off of having additional variables, there should be little question that even this simple function is easier to read and debug. One more point needs to be made about optimization and side effects.
Specifically, in the pre-extracted example, if the value of x is 0 at runtime then the program will know immediately after evaluating it that the if() statement will be false. As such, it will not evaluate abs(y), let alone compare it to 20. In the post-extraction version, both abs(x) and abs(y) will be evaluated. This is only relevant if the execution of the second function were to produce any side effects. If so, then things like state and execution time will be similar, regardless of the values of x and y, in the second version.
In this case, not only is readability improved, but predictability is, as well.
Class Extraction
The extraction of a class is something more likely to be done manually. Once it’s recognized that a group of variables, in particular primitives, are being used together for a common purpose, it’s time to create a class.
For example, if an accounting system is based on dollars then there may be a set of simple variables and standalone functions in use, such as:
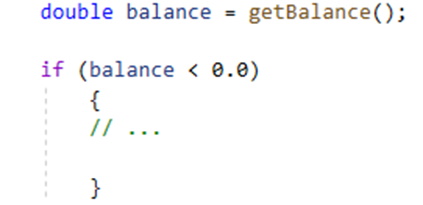
Figure 11: Accounting system code snippet
Over time, the system grows and at one point, the functionality supports multiple currencies with different exchange rates and it keeps track of what each exchange rate was at the close of a specific date. Doing so would require several more related primitives and functions, and would therefore be an ideal place to extract them into a class.
Having a “balance” class would incorporate variables for the amounts, exchange rates, and relevant dates, along with methods for initializing, checking, and reporting them.
Inlining
Inlining is another refactoring method, and it’s really the opposite of extracting. Consider a case where the body of a function is so trivial that it is more understandable than the function call. This generally doesn’t happen by design. In practice, a function is created to encapsulate more complex behavior but over time, just as in the case where increasingly complex objects were extracted, those becoming overly simple can be inlined.

Figure 12: Simple function that can be inlined
Instead of having the getBalance() function act as a wrapper, it may be simpler to use the inline version:
In this case, having fewer functions makes the code simpler to read.
Moving
Moving objects is the type of refactoring that is normally used when one variable or method is being used by more than one class. For example, if class A uses a method in class B, more than class B uses it, then it makes sense to move the method. Class B can instead use code to reference the new method or even remove it, depending on the level of refactoring.
C++ Refactoring – Summary
Code refactoring is an important step in preventative maintenance that improves an existing codebase without changing its functionality. There are many benefits although when it comes to refactoring, sometimes you do it, and sometimes you don’t. Despite C++ being more difficult to refactor than a language like C# or Java, the benefits justify the effort. In cases where you do, plan accordingly because it might take longer than expected to complete. As with any coding, hidden challenges inevitably arise.
Many refactoring techniques are available and although we only cover the basics here, it is enough to get you started. At the very least, you know that there are modern IDEs and extensions available to help you along the way.
In the spirit of keeping things simple, we’ll end it right here.
