
In his blog how-to-create-efficient-c-parallel-builds, Dori refers us to Chandler Carruth’s excellent CPPCon 2019 talk titled “There Are No Zero-cost Abstractions”. As Dori points out and Chandler demonstrates, we may very well think about code efficiency and its ecosystem of build, testing, and release in terms of three key measurements: run time, build time, and of course human time.
If you haven’t watched Chandler’s talk, he gives an interesting test case of pre-Move Semantics in C++11. If you want to read about move semantics, this one is nice: https://stackoverflow.com/questions/3279543/what-is-the-copy-and-swap-idiom. If this is too basic for you, perhaps you know a C++ beginner who would enjoy it 🙂
Build Time and Run Time

Run time is straightforward and obvious. We all learned to consider it when writing a computer program or algorithm. Build time is also important and sometimes critical. Most of us have only realized this when first working on relatively large-scale codebases. Waiting for a build to complete is simply a waste of time. If you disagree, just think about 6 engineers waiting for a build that takes 10 minutes – that’s 60 minutes of engineer time that is wasted, given, their ability to improve or analyze the code is completely put on hold or at least significantly restricted. Now, multiply this wasted time in the number of times the code is being built throughout the day, the week, the month… This is a major cost in human time! We will return to this example with a solution that will keep you ahead of the game.
There is of course an obvious trade-off between the two. To improve run time we need to use compiler optimizations that will generate more efficient code. The good news is, that nowadays compilers are doing an excellent job in code optimization, but this of course comes with a cost – extra build time.
A possible gcc compilation command (for clang optimizations click here) that aims for code optimization may very well look similar to this:
gcc -O2 -flto (flto for LinkTimeOptimization, which we will discuss later).
Note that -Og (instead of -O2) according to GNU’s manual is the recommended optimization level for the standard edit-compile-debug cycle. It offers a reasonable level of optimization, while maintaining fast compilation, and good debugging capabilities. -O0 (the default) also reduces compilation time and may assist in debugging, as the compiled binary is “closer” to the source code flow and logic. However, according to GNU, -Og would be a better choice as it holds more debugging information than -O0. The optimization flags: -O1, -O2, -O3 (for a full description of optimizations see: https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html), in this order, each adds more optimizations to the previous ones. For example, -O3 will perform all of -O2 optimizations plus a few more. Optimizing more will typically cost us in build time. In the context of this run-time / build-time trade-off, it is also worth mentioning that many find that the -O3 extra build-time does not justify the gain in performance and still use -O2. The less common -Ofast option is also evidence for this trade-off.
A discussion about performance trade-offs isn’t complete without it mentioning the run-time / code-size tradeoff. The -Os optimizes code size. It enables all -O2 optimizations except those that often increase code size.
Link Time Optimizations (LTO)
The -flto[=n] option runs the standard link-time optimizer. To be used, -flto and optimization options should be specified in both compile time and during the final link. Object files generated with LTO support are larger than regular object files. This allows further optimizations after object codes have already been created.
Using -flto=jobserver utilizes GNU make’s jobserver mode (see below) to determine the total number of parallel jobs across all executions. This is useful when the Makefile calling GCC is already executing in parallel. You must prepend a ‘+’ to the command recipe in the parent Makefile for this to work. Even without the option value, GCC tries to automatically detect a running GNU make’s jobserver. Use -flto=auto to use GNU make’s jobserver, if available, or otherwise fall back to autodetection of the number of CPU threads present in your system.
For more info and limitations see: https://gcc.gnu.org/onlinedocs/gccint/LTO-Overview.html
Speeding Up Build – Expose Potential Parallelism
GNU Make is able to run multiple recipes in parallel (see Parallel Execution) and cap the total number of parallel jobs, even across recursive invocations of make (see Communicating Options to a Sub-make, https://www.gnu.org/software/make/manual/html_node/Job-Slots.html). It uses a method called the jobserver (good read as an introduction to jobservers: http://make.mad-scientist.net/papers/jobserver-implementation/) to control the number of active jobs across recursive invocations. Note that only command lines that make understand to be recursive invocations of make (see How the MAKE Variable Works) will have access to the jobserver. When writing makefiles you must be sure to mark the command as recursive (most commonly by prefixing the command line with the + indicator (see Recursive Use of make, https://www.gnu.org/software/make/manual/html_node/MAKE-Variable.html)
Let’s See How it Works
The process is simple:
- Prepare a Makefile, where we include recipes, that would each run as its own process. (Recipe – what a great name – let’s keep it :))
- Run: make -j <number of jobs>
For a simple demonstration, we shall use a C++ project which I hope many of you find interesting and relevant. In a future world where a digital currency is trivial, Bitcoin’s C++ code would be a classic. There are alternative methods to solve the consensus problem which are more efficient in terms of the energy required. Therefore, it would have a less negative impact on the environment when compared to the damage created by the excessive amount of energy invested in Bitocin’s proof-of-work. Other methods may also be more efficient when it comes to the time required to generate new blocks and extend the blockchain. Proof-of-stake and proof-of-space are examples to consider. In any case, we must also consider the fairness of coin distribution across the system and allowing anyone supporting the network to be rewarded. These important topics will discuss at another time in the future…
We will use Bitcoin Core, formerly Wladimir van der Laan’s Bitcoin-Qt that is based on the original C++ reference code by Satoshi Nakamoto. An overwhelming percentage of full nodes in the Bitcoin Network are running Bitcoin Core’s code. It is certainly holding the Economic Majority of the network, making it the dominant code that enforces protocol rules.
To build a Bitcoin Core (without a GUI) on Mac OSX follow these steps. For other platform-specific instructions and configuration options see: https://github.com/bitcoin/bitcoin/tree/master/doc/build-*.md
Clone the repository
git clone https://github.com/bitcoin/bitcoin.git
Change directory to bitcoin
cd bitcoin
Install dependencies – Berkeley Database is required for support of legacy wallet addresses
brew install berkeley-db@4
Now Lets configure a Makefile
./autogen.sh
./configure –without-bdb –with-gui=no
Now a Makefile was created for us, and we are ready to compile, N will represent the number of parallel jobs to be executed (one if option is omitted):
make -j N
See the following table of build time in second per number of jobs:
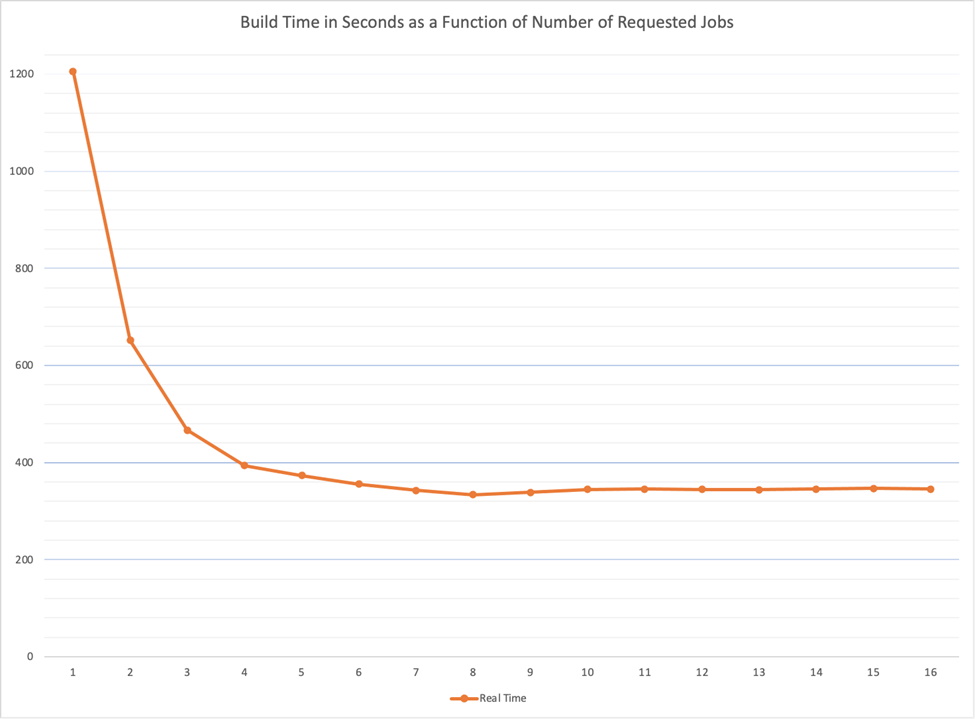 Average build time in seconds per number of jobs performed on a 2.7 GHz Quad-Core Intel Core i7 (with Hyper-threading)
Average build time in seconds per number of jobs performed on a 2.7 GHz Quad-Core Intel Core i7 (with Hyper-threading)
Since this is a quad-core with Hyper-threading, each core can work on two jobs simultaneously, so we have a potential of 8 jobs parallelism. It is therefore not surprising to see that on a low-loaded machine, build time is faster as we increase the number of requested jobs up to 8. As we ask for a number of jobs that is greater than 8, there is a small overhead that actually increases the build time.
We can also see from this experiment that the gain in build time is significantly larger when we increase the number of jobs up to the number of cores (4). There is definitely a gain to work with 5-8 jobs but these results demonstrate that Hyper-threading does not double the computing power.
But wait, what if the system is loaded? Remember that parallelism is also be achieved by a simple ‘&’, Ori Hoch wonderfully explains this here: speed-up-your-builds-by-parallelizing
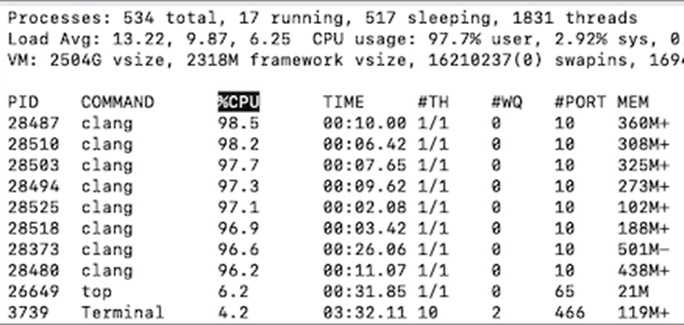
Screenshot of top while executing 8 parallel jobs.
Note the Load Avg in the top screenshot (Image 2), which was captured during the execution of 8 parallel build jobs. Load average at that moment is 13.22, which obviously was not an optimal time to have 8 parallel jobs. This is where the following flag can come in handy:
-l or –max-load
When the system is heavily loaded, you will probably want to run fewer jobs than when it is less loaded. You can use the -l or –max-load options to set a limit on the number of jobs that run simultaneously, based on the load average. The option is followed by a floating-point number. For example: make -j 8 -l 6.5 will not let make start more than one job if the load average is above 6.5. More precisely, before make starts a new job, and it already has at least one job running, it first checks the current load average. If it is not lower than the limit given by ‘-l’, make waits until the load goes below that limit, or until other jobs finish (https://www.gnu.org/software/make/manual/make.html#Parallel).
Conclusion
We have seen that a parallel build is an excellent and crucial tool to speed up builds. The -j option reviewed above was able to significantly speed up build time. However, it would not allow us to extend beyond the boundaries of our machine and utilize more than its own cores.
Now, reconsider our previous example of the 6 engineers forced to be idle and lose precious development time while waiting for the build phase to end. What if they can all take a break together for a drink or a chat and utilize their idle CPUs to collaborate in the execution of a parallel build.
Since you probably already have idle cores in your local network, sometimes even supercomputers with hundreds of cores. What if you had a build system that could harness those idle CPUs and share the load of your parallel build? What if you could use additional computation resources in the public cloud? This is where solutions for distributed builds come in handy, like for example those provided by Incredibuild. We will investigate and discuss parallel distributed builds in our next blogs.
